Part 5 - AWS Cloud Development Kit (CDK)
This post will be the final post in the F# for the cloud worker series. There are of course many more things to cover in this space (F# and cloud), but this will be done a bit different than the approach has been in these posts. Despite the challenges with being a .NET newbie in a realm infested with C#, I like F# and I do want to use it more, including Cloud-based solutions. My regular day job tends to be more oriented towards languages such as Go, Python and Typescript though -and R for a research project.
In this final post, we will continue our journey of using F# for different types of cloud solutions, with a focus on AWS. In part 4 we touched a bit on infrastructure-as-code definitions, using AWS Cloudformation and AWS Serverless Application Model (SAM).
We are going to continue with infrastructure-as-code and jump into using AWS Cloud Development Kit (CDK). With the CDK, we are going to define a simple HTTP-based API that keeps track of the number of requests for different paths. We are going to use AWS API Gateway, AWS Lambda and DynamoDB for this example and set up these resources with AWS CDK.
AWS CDK is to some extent a response to limitations and concerns for formats like Cloudformation YAML/JSON, which can be cumbersome to manage as infrastructure solutions grow in size and complexity. The idea is that by using regular programming languages instead of YAML/JSON to describe the infrastructure, it can take advantages of complexity management that programming languages may support better than plain structural formats like YAML and JSON.
A counter-argument is that it may become more difficult to see what kind of infrastructure is described by the program code, since more complex structures and expressions may be described by regular programming languages.
The CDK is a framework that lies on top of AWS Cloudformation - the code written will generate Cloudformation as a result of it being executed. This means that the declarative model of Cloudformation is still thee under the hood, and this is a good thing. It will make it possible to reason about what an impact a code change has to the infrastructure since it is possible to compare the difference of the newly generated Cloudformation with the old one.
This also means that one still needs to know Cloudformation to reason and understand the impact of changes.
The CDK is written in Typescript, but through an interface layer called JSII it exposes the Typescript code to a few other languages. Note that the language interface layer is only between Typescript/Javascript and other languages. This makes Typescript a bit more privileged language.
There are JSII mappings to Python, .NET and Java for the CDK. In this post, we are going to explore using the .NET version of CDK with F# to define some infrastructure as F# code.
AWS CDK concepts
There is an introduction of AWS CDK and its concepts in the AWS documentation, if you are unfamiliar with the CDK this may be a useful read. There is an overview picture in these docs that shows the general concepts:
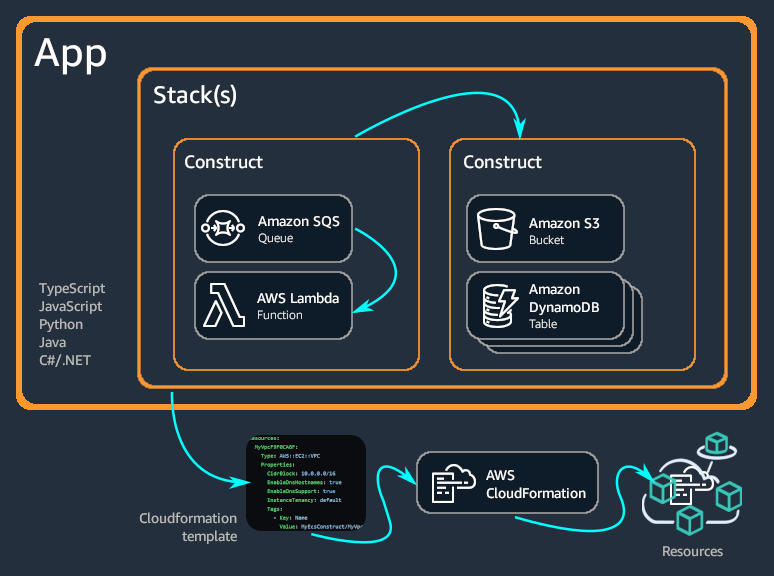
When the AWS CDK is used, you work with something called an Application. This is the main container for everything that belongs together. Within an Application, there are one or more Stacks. This is collections of infrastructure resources that are typically somewhat tightly coupled. A single instance of a Stack is always deployed to a single AWS account and region and maps to a Cloudformation stack.
A CDK Stack contains one or more Constructs. This is a logical entity which can encapsulate multiple AWS resources and logic for setting these resources appropriately. A construct can also be built up with other constructs to create higher-order constructs. In this way, it is possible to package re-usable patterns/solutions conveniently. The CDK itself contains many such constructs that make some patterns or scenarios much easier to set up than with plain Cloudformation.
When the code is compiled and then executed, the output from that execution is Cloudformation templates. These are then deployed to the AWS accounts and regions of choice using the CDK CLI.
Set-up of AWS CDK
AWS CDK consists of a set of packages/libraries and a command-line interface (CLI) tool. Similar to the libraries themselves, the CDK CLI tool is written in Typescript and needs to be installed via the tool npm, which is the most popular repository and package management solution for the Node.js ecosystem. If you already have npm (and thus also node.js) installed, then you can continue to next step below. If not, have a look at these installation instructions and pick an option there.
Once npm is available, it is time to install the AWS CDK command-line tool. This can be done in a local (npm project-specific) or global install. If you were to write the rest of the project with Typescript/Javascript, or something that produces Javascript code, then a local install may make sense. If using npm is just to be able to get the CDK CLI tool, then a global install is likely more suitable.
To install the latest version of the AWS CDK CLI tool with a global install, run
npm install -g aws-cdkThis will make the cdk command available to use. Run cdk version to make sure it is installed properly and accessible:
~ ❯❯❯ cdk version
1.63.0 (build 7a68125)
~ ❯❯❯ Creating a CDK project for F
To set up a CDK-based solution/project a starting point is the cdk init command:
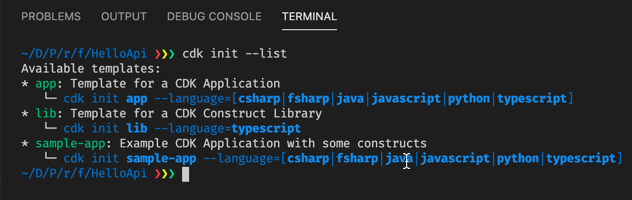
The app option is what is used for a default empty CDK project set-up. Note: Currently, the cdk init command must be executed in an empty directory, otherwise it will fail.
Let us set up a CDK-based solution called HelloApi, where we will expose a simple REST API using AWS Lambda, API Gateway and DynamoDB. The first step is to create an empty project:
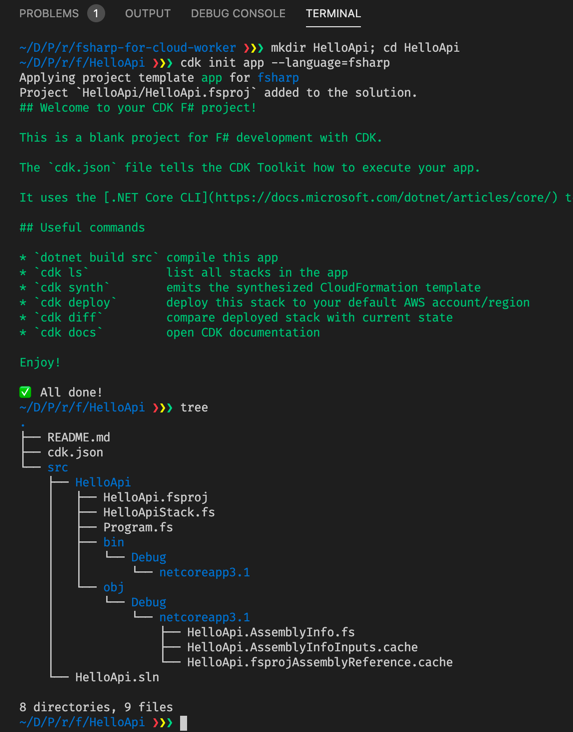
This is somewhat similar to the projects created by the dotnet lambda tool in previous posts. There is no separate test project though and there is a HelloApi.sln file. This is a solution file and one which comes from Visual Studio and contains information to group multiple projects.
There is a file cdk.json, which is important for our CDK applications and which we will get back to later. The README.md file gives some info on using the CDK CLI. There are two files for our code, Program.fs and HelloApiStack.fs. This is where we will start.
Working with CDK code
First, note here. While technically it is possible to write CDK code and the CDK itself contains starter templates for F# code, AWS also states in their documentation that they currently only provide official support for C# when it comes to .NET. Thus any documentation and information for the CDK need to be based on C# documentation and examples and translated into F# context. The only pieces of F# to be found in CDK is the starter templates.
From a learning perspective, this means one has to learn some C# and C# - F# interoperability (on C# terms).
Let us start with Program.fs, our main program file:
open Amazon.CDK
open HelloApi
[<EntryPoint>]
let main _ =
let app = App(null)
HelloApiStack(app, "HelloApiStack", StackProps()) |> ignore
app.Synth() |> ignore
0In this file, we have a function main which is marked with the attribute EntryPoint. This is how the starting point of the program is marked. This also needs to be the last function in the last source file of the program. The expected input data to this function are the command line arguments, which is an array of strings. Since this application itself does not use any command line arguments, the input parameter is specified as _ (underscore), meaning that it will be ignored.
The first line, let app = App(null), creates an instance of the App class, which is the container for all infrastructure code. The next line creates an instance of the HelloApiStack class. The first parameter the constructor here and to any Stack or Construct constructor is the parent object. For stacks, the parent will generally be the App instance. The second parameter is the name of this object and the third any input properties to provide to this stack.
Note that the programming model in CDK is quite object-oriented and essentially focused on creating objects, plus potentially changing the state of the objects after creation. This is quite far from typical functional programming.
The third line calls the __App.Synth()_ function, which is the part of the code that takes the App object and its state and generates Cloudformation templates from it. The final 0 is then just to indicate that the main function is successful.
The results from creating the HelloApiStack instance and from running App.Synth() is ignored - we do not need it in this case.
Let us continue with HelloApiStack.fs:
namespace HelloApi
open Amazon.CDK
type HelloApiStack(scope, id, props) as this =
inherit Stack(scope, id, props)
// The code that defines your stack goes hereThis code declares a namespace for the Stack and then the boilerplate for declaring the HelloApiStack class itself. The class inherits from the CDK-provided base class for stacks. The as this part is so that the name this can be used later in the code when the code itself needs to reference this object - which it will be.
And here it is time for us to go through the build and deploy steps with the empty CDK app.
Build and deploy CDK app
At the top level of our file hierarchy within HelloApi, we have a file named cdk.json. This file is important to the CDK and when we execute CDK CLI commands, we should do that from the directory of the cdk.json file. Let us have a look at the content of the file:
{
"app": "dotnet run -p src/HelloApi/HelloApi.fsproj",
"context": {
"@aws-cdk/core:enableStackNameDuplicates": "true",
"aws-cdk:enableDiffNoFail": "true",
"@aws-cdk/core:stackRelativeExports": "true"
}
}For the time being, the key field for us here is the app field. This specifies what should be executed by the CDK CLI to produce the Cloudformation template it will use towards AWS itself. The dotnet run command in here tells it to use the dotnet command to build and run the code in the HelloAPi project. The other entries within the context structure we can ignore for now.
So let us change directory in a command-line window to that of the cdk.json file and execute three different CDK CLI commands:
- cdk synth - This will execute the CDK app code and produce a Cloudformation template, which is shown in the output of the command.
- cdk deploy - This will deploy a Cloudformation stack, based on the generated Cloudformation template generated by the CDK code. The command will print out progress information and wait for the deployment to finish.
- cdk destroy - This will delete the deployed Cloudformation stack from the AWS account.
Note that the generated Cloudformation does not contain any actual resources at this point - it just generates a bit of metadata which is always attached to any Cloudformation template that is generated by the CDK. Note also that it is not required to run the cdk synth command before running cdk deploy. The Cloudformation template creation will happen anyway with the cdk deploy and synth is just if you want to have a look at the generated Cloudformation.
Adding more infrastructure
A backend Lambda function
Now, let us add a Lambda function to call. Technically we could add a function for any language, but since we are doing F# we will, of course, add a Lambda function written in F#. Let us add a Lambda function, using a template similar to what we did in part 3.
These things may be done through the IDE, which may be a bit different depending on IDE. I will though focus on using the dotnet cli, which is independent of the IDE you may use.
We start from the root directory of our HelloApi file structure, same directory as the cdk.json file. First, create a project for a Lambda function:
dotnet new lambda.EmptyFunction --output . --name Backend --language "F#"We call the project for the Lambda function Backend and the template generation should be in the current directory. After execution, we should have this file structure:
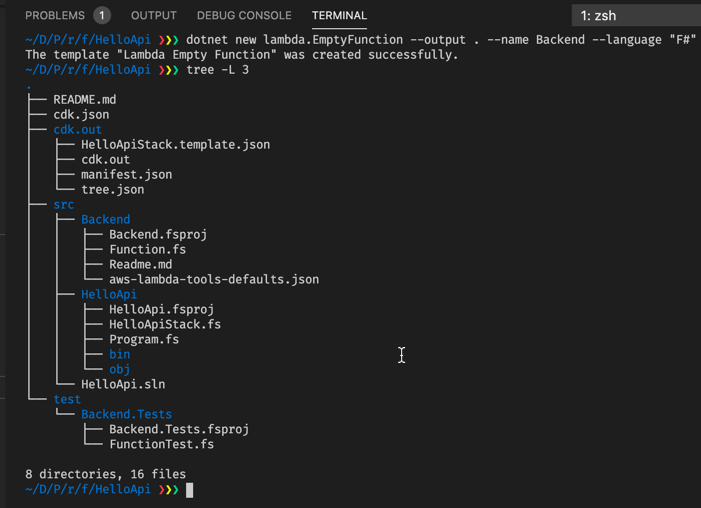
Let us also add the Backend project to our solution (HelloApi.sln):
dotnet sln src/HelloApi.sln add src/BackendWe now have two projects in the solution.
Next, we are going to add some infrastructure code for the Lambda function. In CDK, each AWS service has its package to include. For Lambda service, this is Amazon.CDK.AWS.Lambda. So we add this package (switching to directory of HelloApi project):
dotnet add HelloApi.fsproj package Amazon.CDK.AWS.Lambda
Now, we can add the infrastructure code for our Lambda function. To our assistance, we have the CDK API Reference documentation for .NET (C#). From Amazon.CDK.AWS.Lambda module, we need to create a Function object. There are a few items that we have to set and some we may set. There are 3 parameters to a Construct-type constructor:
- Scope - the parent of the construct. This is typically the current object
- id - A name for the construct. This is used as part of name generation in Cloudformation template
- properties - Each type of construct can take several properties which describes how the specific construct shall be configured.
For the scope, we will always use this. For the id part, we pick a name. FOr the properties, there is a FunctionProps class in this case. This class does not include any parameters in its constructor, it only uses properties on the object itself to set any values.
namespace HelloApi
open System
open Amazon.CDK
open Amazon.CDK.AWS.Lambda
open Amazon.CDK.AWS.Logs
type HelloApiStack(scope, id, props) as this =
inherit Stack(scope, id, props)
let funcProps =
FunctionProps(Runtime = Runtime.DOTNET_CORE_3_1,
Code = Code.FromAsset("./src/Backend/bin/Debug/netcoreapp3.1/publish"),
Handler = "Backend::Backend.Function::FunctionHandler",
Description = "Our backend Lambda function",
MemorySize = Nullable<float>(256.0),
LogRetention = Option.toNullable (Some RetentionDays.ONE_WEEK))
let backend = Function(this, "Backend-function", funcProps)Fortunately, F# supports an object initializer syntax which allows us to set fields in the object we create as if they were constructor arguments. There are a few of these fields that are required, others have some (hopefully) sane defaults. It is a stated design goal that CDK constructs should as much good default values as possible, essentially. In our case, we need to specify Runtime, Code and Handler.
For the Code property, we create a Code object that refers to the generated code for the Lambda that is ready for deployment. This is relative to the directory of the cdk.json file, where we will execute the CDK CLI commands.
We need to create deployable output for our Backend Lambda function. In part 3 and 4 this was done with the specific dotnet lambda tool. This one is not adapted for use with AWS CDK and thus we need to do this slightly different. In this case, we will use the dotnet publish command to generate deployable output first. This will generate output in the bin/Debug/netcoreapp3.1/publish directory of the Backend project by default, so this directory is what our Code property will point to. The Handler property specifies the assembly, the type and the method on that type, that is the Lamda handler code. More details can also be found here.
The properties MemorySize and LogRetention looks perhaps a bit weird. The property MemorySize is a float, not an integer, even though only integer values are specified for memory. This comes from the CDK libraries themselves are written in Typescript, with a translation layer between Typescript/Javascript and other languages. In Javascript, numbers are of the number type, there are no separate types for integers and floating-point values. Also, the properties are nullable, i.e. they can have the value null - generally indicating no value.
In F#, types are only nullable if they are explicitly stated to be so. So trying to assign a float value to a variable of a nullable type will fail. Instead, the value must be converted to be a nullable type for this to work.
In F#, value situations where a may or may not have value is typically handled using the Option (generic) type. There are two cases for Option:
- Some value
- None
With value being some kind of value that is used when there should be an actual value. This is similar to using null in some other languages, although more explicit and clear with the types and more pattern matching friendly.
For our second case where we need to deal with nullable values, I have used an Option-based value for the LogRetention and then converted that to a nullable value using the function Option.toNullable. Both of these approaches work. It may look a bit clunky since it is not adapted for typical F# code though.
Note: the do keyword and the indented assignments are required. If the assignments to funcProps would have been written directly under the creation of the funcProps object, there would be an error. The error message is a bit cryptic “unexpected identifier in member definition”, which in reality means “assignments inside a constructor/member section of a type need to be within a do-block”.
Check the Cloudformation
Now when we have added the code that will set up the resources for the Lambda function itself, we can have a look at what the resulting Cloudformation will be. We run the cdk synth command to get the Cloudformation generated.
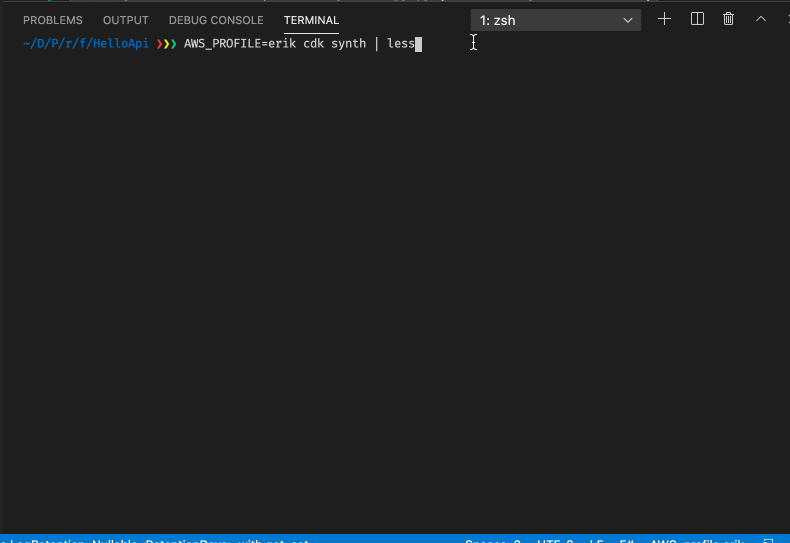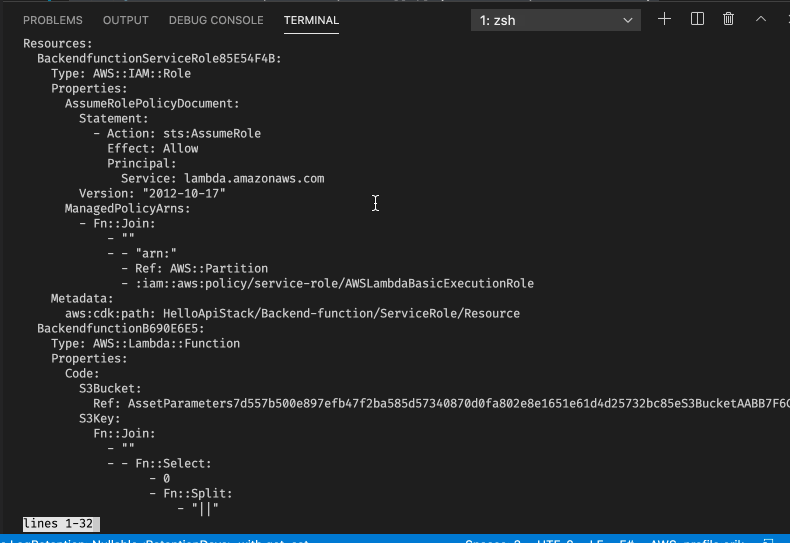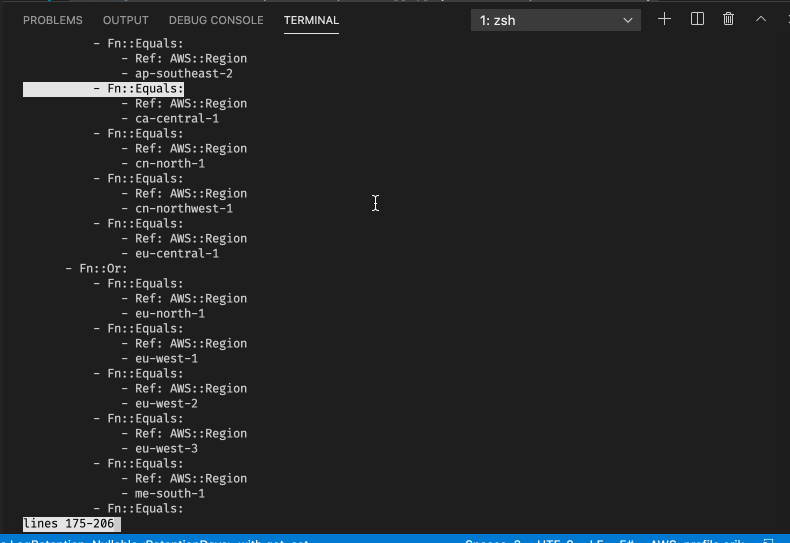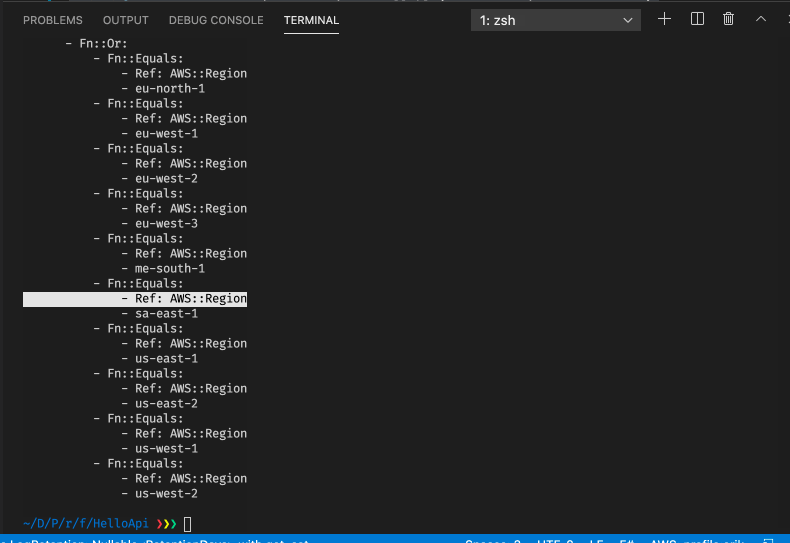
This output a bit over 200 lines of Cloudformation YAML. The code is probably easier to read, but - and this is a big but - it is not easy to see the details of what will be created. At least the Cloudformation will be explicit about what is created. Also, when you do updates of the infrastructure, looking at the Cloudformation itself will not be easy to spot changes. Differences in the code itself will be clear, but may not necessarily be clear what actual resources will change compared to what is already deployed.
In this situation, the cdk diff command may come somewhat handy. Its drawback and strength are that it will show what will change at a Cloudformation level, compared to what is deployed already - or rather what the already deployed Cloudformation stack(s) considers to be the truth. This can be run also for a stack which has not been deployed and in this case, will show what resources will be created.
This may be somewhat easier to get an overview with.
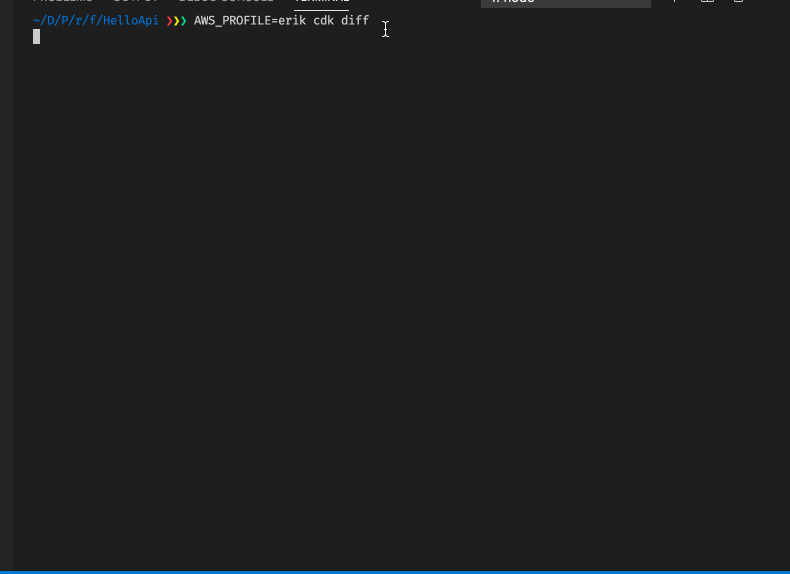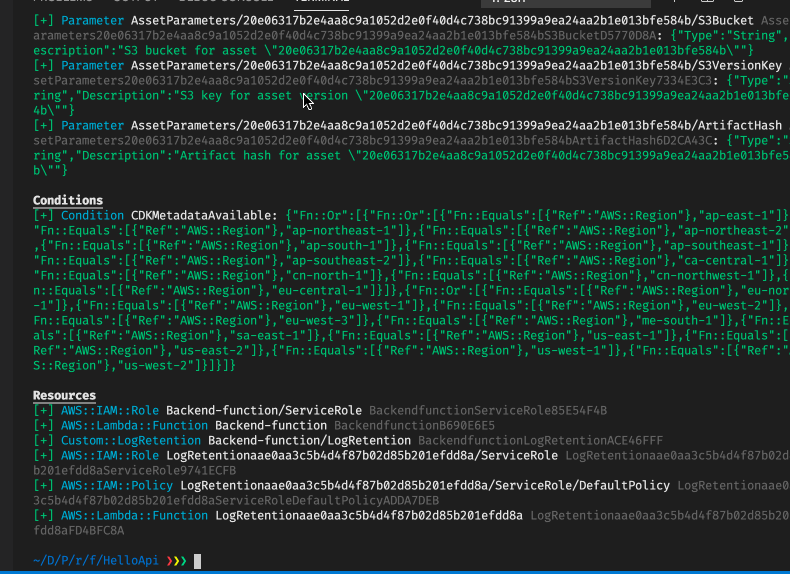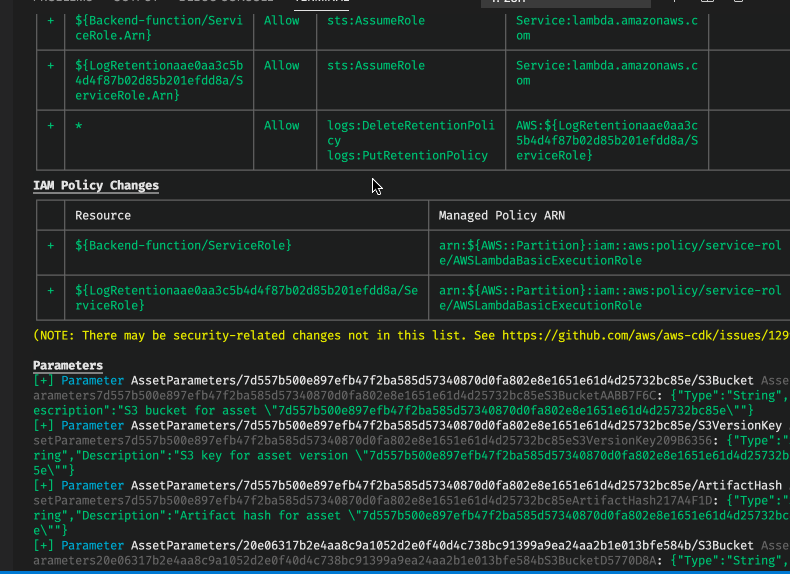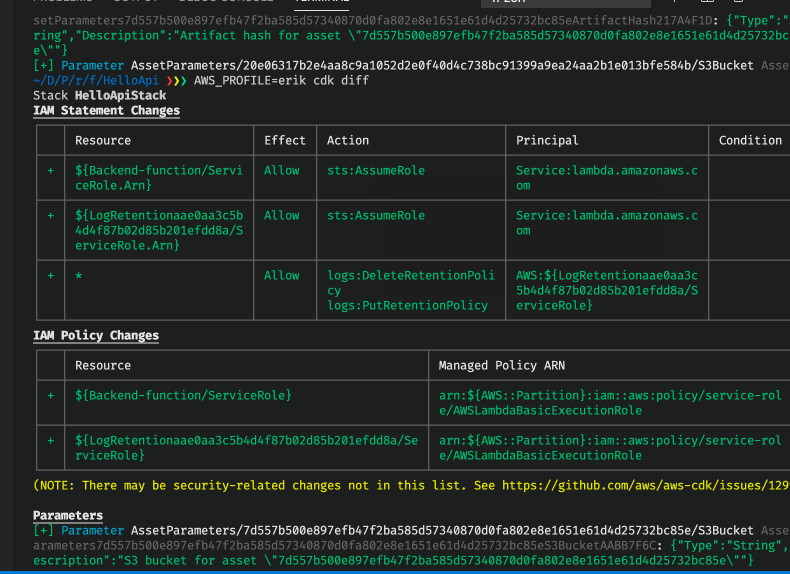
Did you catch in either the CDK diff or in the CDK synth that there are two Lambda functions? It turns out that one of the things that you cannot set directly with Cloudformation is the log retention time for the Lambda function. So in this case the CDK generates and deploys a custom resource and accompanied Lambda function to handle this functionality under-the-hood for you. This is an example of working around shortcomings in Cloudformation which can be packaged rather nicely. Sometimes Cloudformation has some annoying shortcomings, so it is in that case good with manageable ways to overcome these.
First actual deploy
Let us now try to deploy what we have so far and see what happens. First, we need to do a deployable version of our _Backend_project, for which we use dotnet publish on our Backend project.
Then we can continue to deploy our CDK app. This we do with the cdk deploy command.
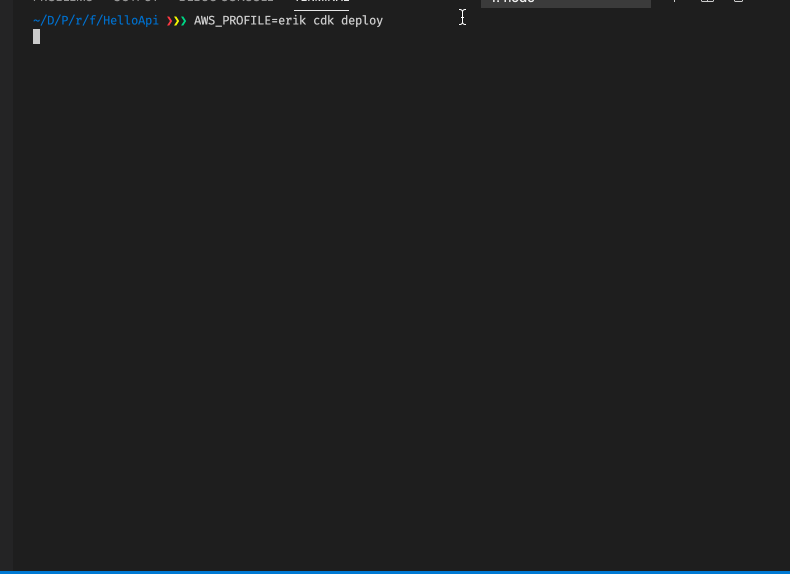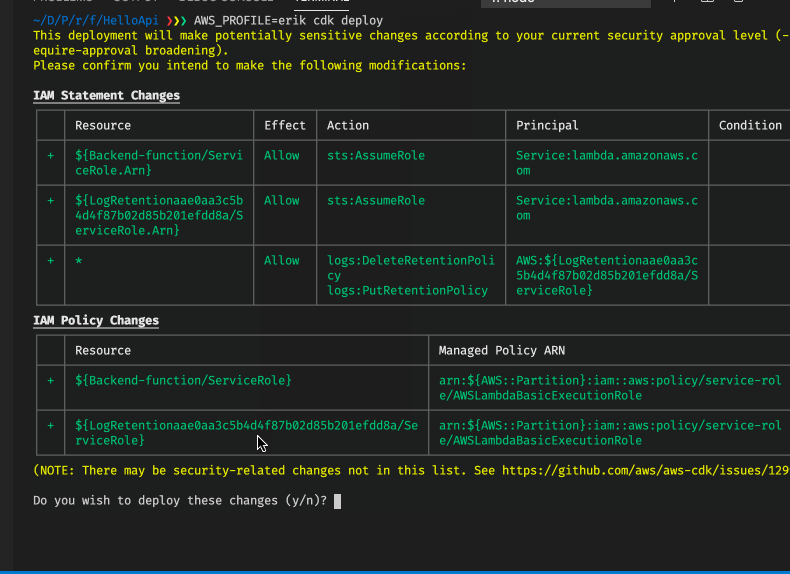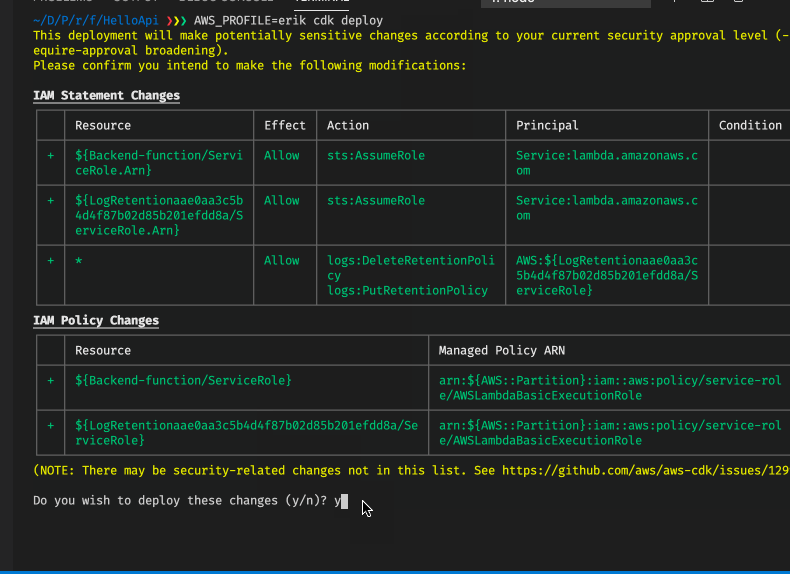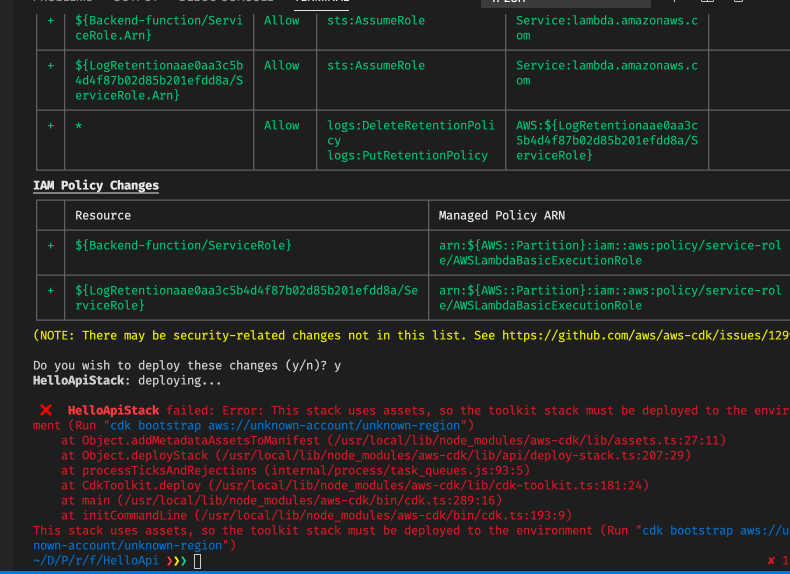
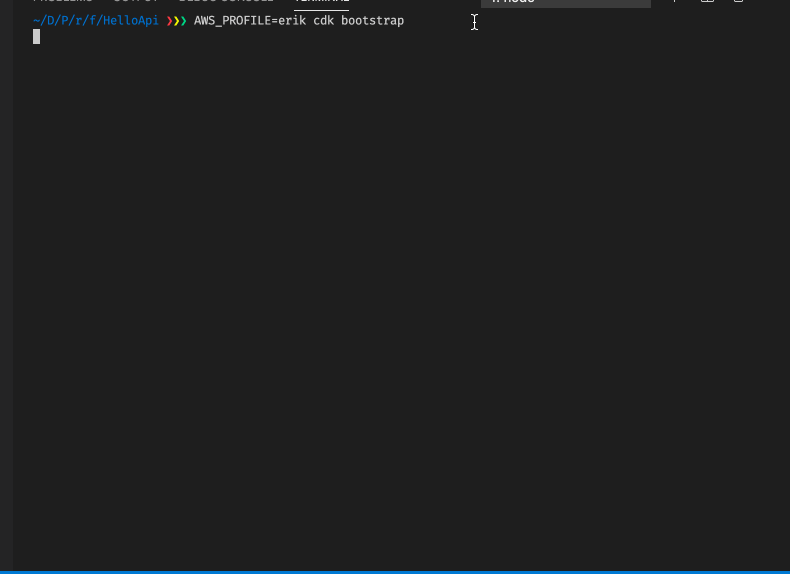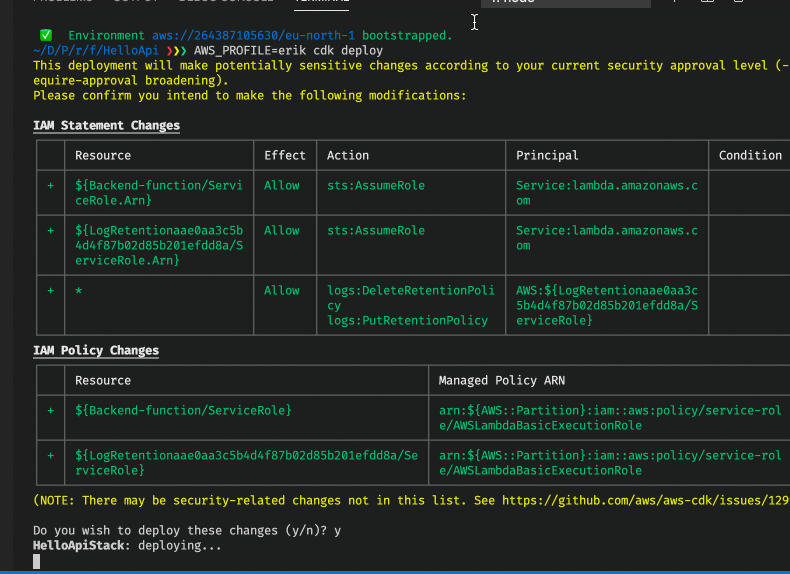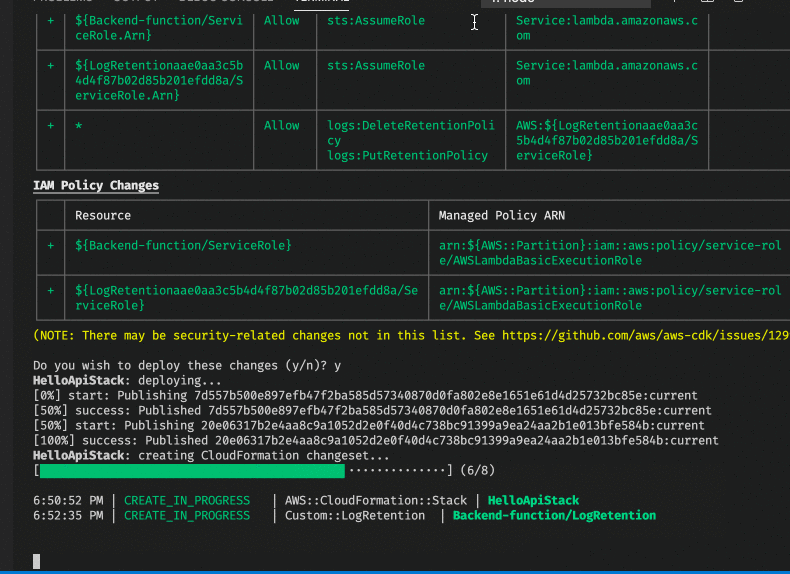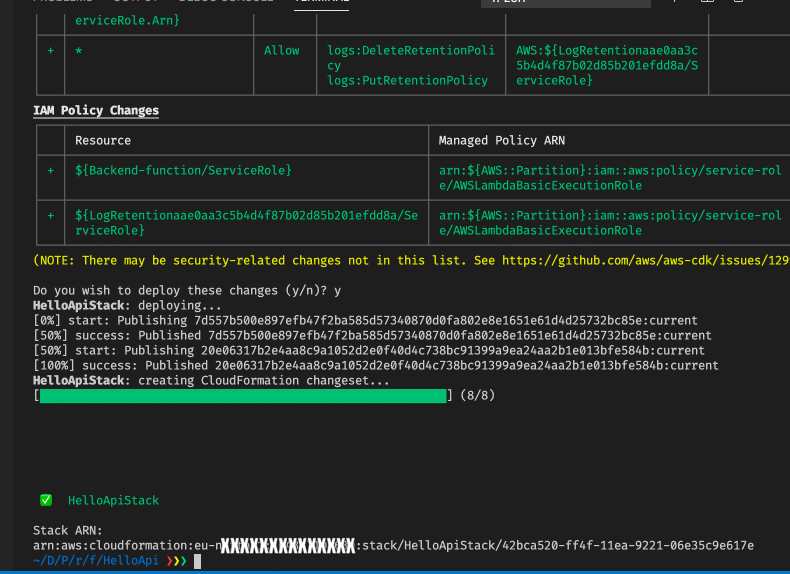
The first thing that happens here is that the CDK CLI lists AWS IAM permission changes that will be done and ask if you want to approve of this. By default, the CDK CLI will ask if you want to continue if there are such changes. The behaviour can also be controlled through command-line option –require-approval. This can be set to three different values:
- never - Always accept any security change automatically
- any-change - Always require manual approval on security changes
- broadening - Only ask for manual approval if a change results in wider/more permissions being set
After that we get an error though - what is that about? This is a limitation within Cloudformation. If we have assets, such as compiled/packaged Lambda functions or just Cloudformation templates which go beyond a certain size, then we cannot just upload everything to Cloudformation directly, we need to upload all these assets to an S3 bucket, which Cloudformation can refer to. We had the same issue in part 4 of this series when we used AWS SAM.
AWS CDK provides a command to set up such a deployment bucket, which is called cdk bootstrap. If you run this command the CDK will set up this bucket for you and will generate a name for it. You can also specify a name it should use if you desire. For multi-developer environments, it can be recommended to be explicit about bucket names so that not everyone creates their bucket for deployment. There will be one bucket per account and region combination.
If we then run cdk deploy after cdk bootstrap it works much better.
We can log in to the AWS Console and have a look at the Lambda section. In there we see two functions, our own Backend Lambda and the CDK-generated Lambda for log retention handling.
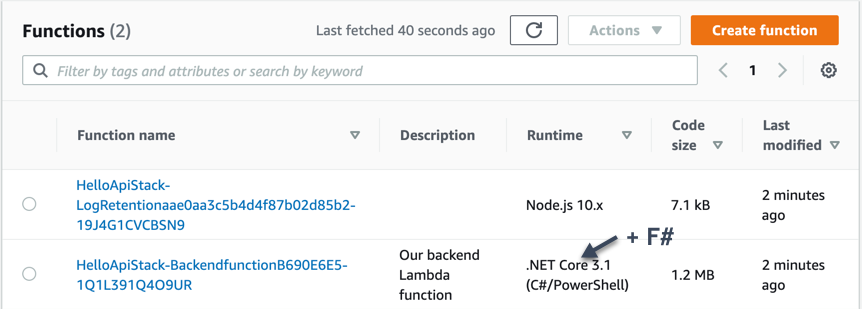
Since we just deployed an “empty” Lambda at first, this will just contain the string uppercase functionality we tested in part 3 and we can similarly test that this one works.
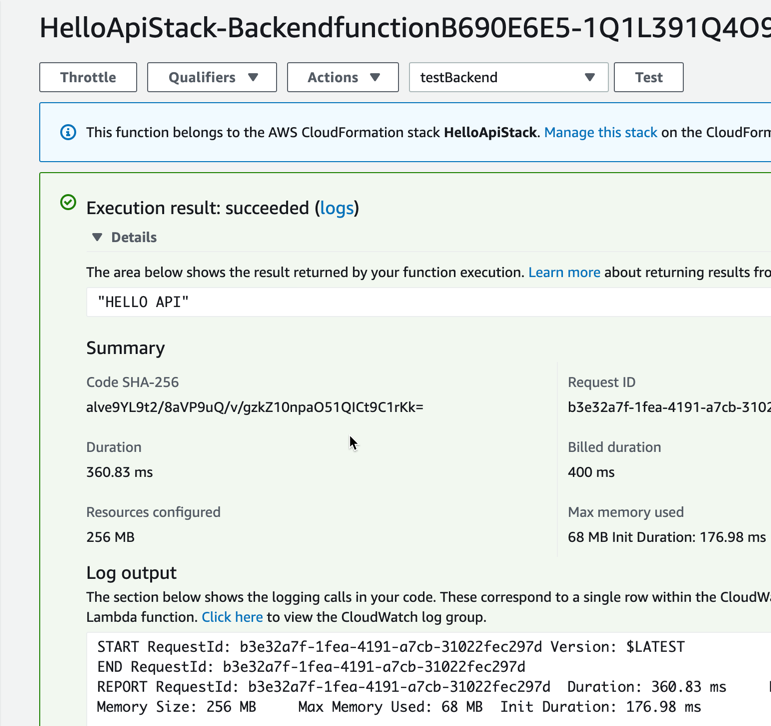
So now we have done the first “real” deploy with the CDK. Let us continue to add more functionality.
Expose Lambda as HTTP API
Next step is to make our Lambda function callable using an HTTP-based API. For this, we will use the AWS service API Gateway. Setting up an API Gateway configuration through Cloudformation is not trivial, since there are a few pieces to put together in that case. Fortunately, the CDK has a convenient construct for this case, called LambdaRestApi. This one takes care of a number of the set-up pieces needed, allowing for fairly minimalistic set-up effort to get something working.
Let us add some code for API Gateway in our HelloApiStack.
namespace HelloApi
open System
open Amazon.CDK
open Amazon.CDK.AWS.Lambda
open Amazon.CDK.AWS.Logs
open Amazon.CDK.AWS.APIGateway
type HelloApiStack(scope, id, props) as this =
inherit Stack(scope, id, props)
let funcProps =
FunctionProps(Runtime = Runtime.DOTNET_CORE_3_1,
Code = Code.FromAsset("./src/Backend/bin/Debug/netcoreapp3.1/publish"),
Handler = "Backend::Backend.Function::FunctionHandler",
Description = "Our backend Lambda function",
MemorySize = Nullable<float>(256.0),
LogRetention = Option.toNullable (Some RetentionDays.ONE_WEEK))
let backend =
Function(this, "Backend-function", funcProps)
let apiProps =
LambdaRestApiProps
(Description = "A simple example API backed by lambda using CDK",
EndpointExportName = "hello-api",
Handler = backend)
let gateway = LambdaRestApi(this, "api", apiProps)The initialization of this construct follows the same pattern as for the Function construct. We reference the parent construct provides an instance name and specific properties for this construct. The properties include a reference to the Function instance, a description and an export name for the API. Since there is a new module for API Gateway, that also needs to be added to the project:
dotnet add HelloApi.fsproj package Amazon.CDK.AWS.APIGatewayWith this piece of code added with can check out what additional resources this will result in, using the cdk diff command.
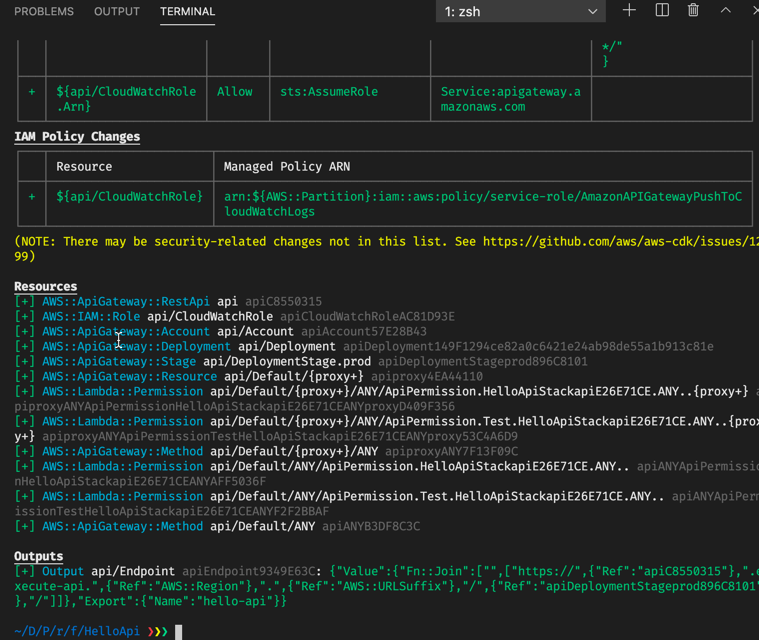
Note here that there are many resources and permissions added, even though we have not specified these explicitly. The CDK provides defaults for a lot of the set-up, which in these type of cases will make it quicker to get something working than with plain Cloudformation. AWS SAM does provide a bit of convenience resource as well, but not to the same extent as the CDK, in this particular case.
Adding this is nice and easy, but this also means we have to adjust the Backend Lambda - it now expects a string as input and returns a string as output. However, input data and return data when integrated with API Gateway is a different matter. It was not trivial to find out what the input data and the return data should be in this case. The AWS documentation for Lambda handlers for .NET (C#) is a bit vague on the topic and I needed a bit of google-fu and dust off old memories to get to aws-lambda-dotnet, which provides more detailed information.
The answer here is to use add the NuGet package Amazon.Lambda.APIGatewayEvents and to use the APIGatewayProxyRequest and APIGatewayProxyResponse classes.
Let us make a very simple implementation - if the HTTP method is GET, then return status code 200 (ok), if the HTTP method is anything else, then return 400 (client error). Also, let us log some of the incoming data and the status code we produce.
namespace Backend
open Amazon.Lambda.Core
open Amazon.Lambda.APIGatewayEvents
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[<assembly: LambdaSerializer(typeof<Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer>)>]
()
type Function() =
member __.FunctionHandler (request: APIGatewayProxyRequest) (context: ILambdaContext) =
context.Logger.Log(sprintf "HttpMethod: %s, Path: %s" request.HttpMethod request.Path)
let response = APIGatewayProxyResponse(StatusCode = if request.HttpMethod = "GET" then 200 else 400)
context.Logger.Log(sprintf "Response statusCode %d" response.StatusCode)
responseThe first parameter to the FunctionHandler function is now changed to be of type APIGatewayProxyRequest and we have given a name to the ILambdaContext parameter since we will use it. We log the path specified and the HTTP method from the request, then create a response object of type APIGatewayProxyResponse where we set the StatusCode field depending on the HTTP method of the request. Then we log the status code and return the response object.
To rebuild the Backend Lambda function, we can run
dotnet publish src/Backend/Backend.fsprojand then run
AWS_PROFILE=erik cdk deployto deploy the changes. We can run a simple test using the command-line tool curl to trigger a successful case (status code 200) and an error case (status code 400):
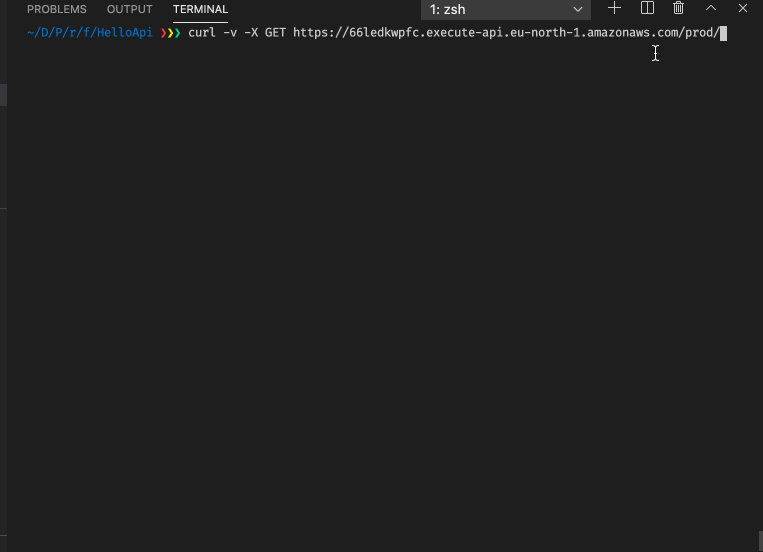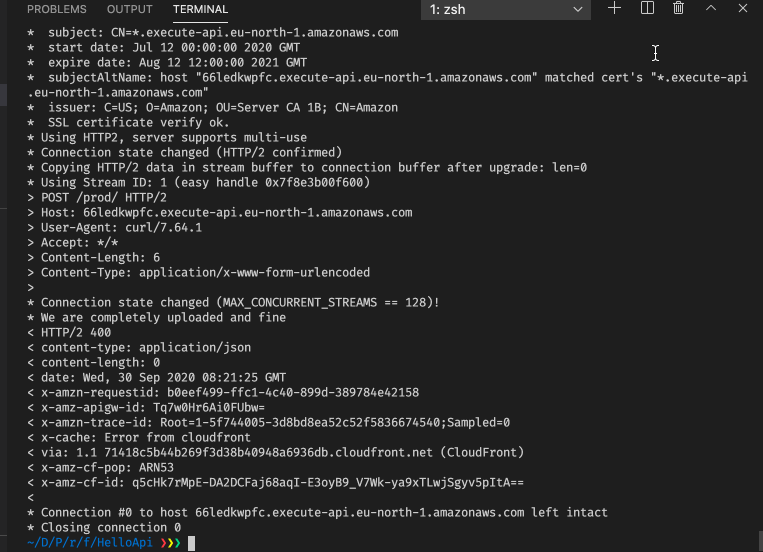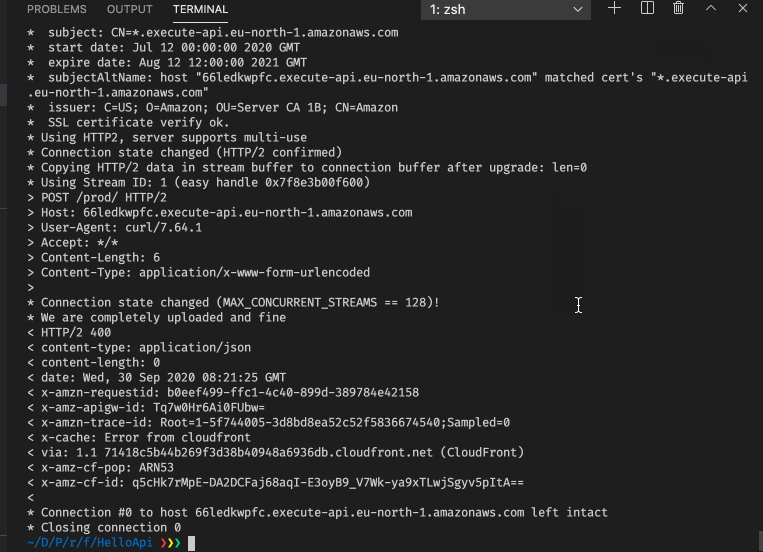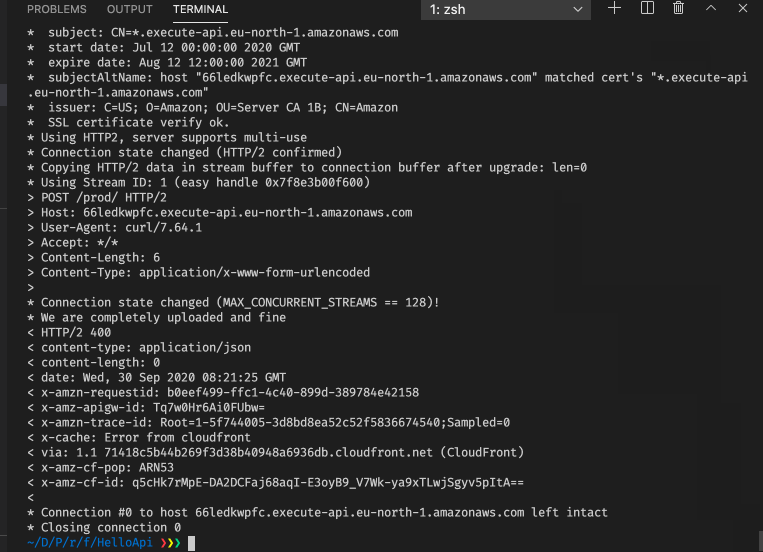
We can also see in the Cloudwatch logs that we have a successful case and an error case.
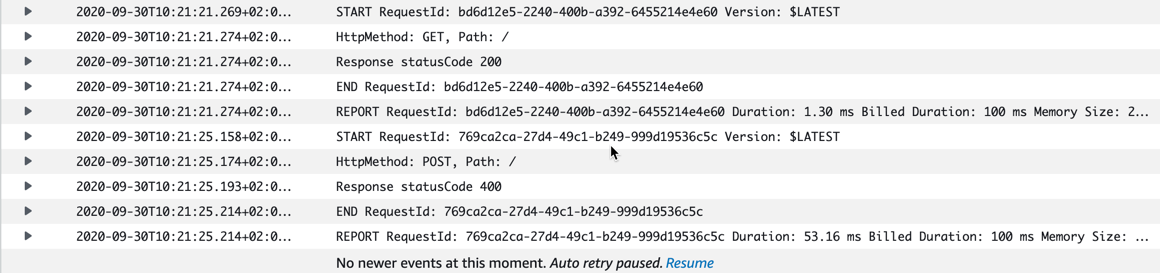
So far, so good. Next step, add some persistence to our API.
Storing hit counts in DynamoDB
The infrastructure
Next, we need to set up a DynamoDB table to store our hit counts for different paths. We need to add another CDK package for DynamoDB, Amazon.CDK.AWS.DynamoDb. DynamoDB is a managed key-value database, where data is stored in tables. Each table have records (called items), which consists of some kind of key entry, either a single field (partition key) or a compound key (partition key + sort key). In addition to that, each item can consist of many attributes, with different data types. New attributes can be added on the fly, but a created attribute will always have the same data type once created.
In our case, we will store the paths used to call our API endpoint and store the number of times each path has been called, with a GET request. This was we also can test this easily through a web browser.
So in our HelloApiStack.fs we should add some code to create a DynamoDB table, which have a key field for the path of the API call. This is pretty straightforward:
let tableProps = TableProps (PartitionKey = Attribute(Name = "path", Type = AttributeType.STRING))
let table = Table(this, "msgdata-table", tableProps)We have not set an actual name for the table itself (“msgdata-table” is just part of the reference to the table in the resulting Cloudformation template), so Cloudformation will generate a name when the infrastructure is deployed. Without setting an explicit name, we could deploy multiple separate setups of this CDK App, even to the same AWS account. They will all get different names.
But the Lambda function we deploy needs to know the name of the DynamoDB table it should write to, so how do we fix that?
One way is to pass the table name through an environment variable. When we deploy the infrastructure, we will have the name when the table has been created. We can then take that name and pass it through an environment variable in the Lambda function configuration. Thus the Lambda function can read the variable and pick up the name of the table when it is executed.
The Lambda function also needs permissions to update the DynamoDB table, so we need to give the Lambda permissions for this specific table as well. Luckily this can be done pretty easily with the CDK.
do backend.AddEnvironment ("TABLE_NAME", table.TableName) |> ignore
table.GrantReadWriteData (backend) |> ignoreWe pipe the result of each expression to ignore, since we do not care about the result data.
The backend lambda
The Backend Lambda needs some code updates to update the DynamoDB table:
- Initialize a DynamoDB client object to make calls to DynamoDB service
- Get the name of the DynamoDB table from environment variable TABLE_NAME
- Build and execute a request to update hit counter for a record in the table
- Check the result and return a status
The whole code for the Lambda is below and we will go through the different pieces after that.
namespace Backend
open System.Collections.Generic
open System.Net
open Amazon.Lambda.Core
open Amazon.Lambda.APIGatewayEvents
open Amazon.DynamoDBv2
open Amazon.DynamoDBv2.Model
// Assembly attribute to enable the Lambda function's JSON input to be converted into a .NET class.
[<assembly: LambdaSerializer(typeof<Amazon.Lambda.Serialization.SystemTextJson.DefaultLambdaJsonSerializer>)>]
()
type Function(dynamoDbClient: IAmazonDynamoDB) =
new() =
Function(new AmazonDynamoDBClient())
static member CreateUpdateItemRequest tableName key =
let updateExpression = "ADD hits :incr"
let keyAttribute = Dictionary(["path", AttributeValue ( S = key )] |> Map.ofList)
let eav = Dictionary([":incr", AttributeValue ( N = "1" ) ] |> Map.ofList)
UpdateItemRequest(TableName = tableName,
Key = keyAttribute,
UpdateExpression = updateExpression,
ExpressionAttributeValues = eav)
static member UpdateTable (dynamoDbClient: IAmazonDynamoDB) (request: UpdateItemRequest) =
async {
let! response = dynamoDbClient.UpdateItemAsync(request) |> Async.AwaitTask
return response
}
member __.FunctionHandler (request: APIGatewayProxyRequest) (context: ILambdaContext) =
context.Logger.Log(sprintf "HttpMethod: %s, Path: %s" request.HttpMethod request.Path)
let tableName = System.Environment.GetEnvironmentVariable("TABLE_NAME")
let response =
if request.HttpMethod <> "GET" then
APIGatewayProxyResponse(StatusCode = 400)
else
let dbrequest =
Function.CreateUpdateItemRequest tableName request.Path
let dbresponse =
(Function.UpdateTable dynamoDbClient dbrequest)
|> Async.RunSynchronously
let statusCode = dbresponse.HttpStatusCode.ToString()
context.Logger.Log(sprintf "DynamoDB response code: %s" statusCode)
APIGatewayProxyResponse(
StatusCode =
if dbresponse.HttpStatusCode = HttpStatusCode.OK then
200
else
555)
context.Logger.Log(sprintf "Response statusCode %d" response.StatusCode)
responseThe DynamoDB client object is something we can re-use, we do not need to initialize this on each call to the handler function. So we construct that object in the parameter-less constructor of Function class, similarly to how we did this in part 4 of this series:
type Function(dynamoDbClient: IAmazonDynamoDB) =
new() =
Function(new AmazonDynamoDBClient())We need to get the name of the table, which is straightforward:
let tableName = System.Environment.GetEnvironmentVariable("TABLE_NAME")For the actual update of the DynamoDB table, we split this into two functions
- One function to build the request itself
- One function to call DynamoDB service
In this way, we separate the concerns and we have one pure function (build the request) and one impure (call DynamoDB service). Also, to keep the design more functional, I choose to implement these functions as static member functions on the Function class. Thus no implicit data from the class itself is available to the functions and they are passed as parameters to the functions.
First the function to create the request itself:
static member CreateUpdateItemRequest tableName key =
let updateExpression = "ADD hits :incr"
let keyAttribute = Dictionary(["path", AttributeValue ( S = key )] |> Map.ofList)
let eav = Dictionary([":incr", AttributeValue ( N = "1" ) ] |> Map.ofList)
UpdateItemRequest(TableName = tableName,
Key = keyAttribute,
UpdateExpression = updateExpression,
ExpressionAttributeValues = eav)We pass the table name and the name of the key attribute in this table to the function. In the function, we create an UpdateItemRequest object, which is returned. We include an expression to update the hits attribute, using the expression reference “:incr”, which we assign the value 1. Two types of interfaces can be used for DynamoDB - the Document API and the low-level API. For this simple very simple interaction, I did not see much benefit with the Document API, but if you are doing more complex operations on items in DynamoDB, that may be an option to look at.
The data structures used to describe the attributes through the low-level API are based on System.Collections.Generic.Dictionary, which is not the same as the F# map/dict structures. This comes a bit more natural if you use C#, but not as much with F#. So there is a bit of a conversion to be done here. It would have been slightly easier if the .NET SDK had used IDictionary interfaces rather than actual class references for Key and ExpressionAttributeValues, but that is not the case. Maybe there are simpler ways to create these dictionary objects - I ended up with an approach which to me is pretty readable and not too convoluted. The approach is to create an F# list of key-value tuples, convert it to an F# Map. An F# Map has an IDictionary interface. One of the Dictionary constructors takes an IDictionary as parameter, so this way I created the required object.
The other function to define is the actual call to AWS DynamoDB service. This follows a by now familiar pattern:
static member UpdateTable (dynamoDbClient: IAmazonDynamoDB) (request: UpdateItemRequest) =
async {
let! response = dynamoDbClient.UpdateItemAsync(request) |> Async.AwaitTask
return response
}These functions are called from the main handler function, which executes these if the HTTP request is a GET request. The outcome of the DynamoDB updates determines what the return status will be:
let response =
if request.HttpMethod <> "GET" then
APIGatewayProxyResponse(StatusCode = 400)
else
let dbrequest =
Function.CreateUpdateItemRequest tableName request.Path
let dbresponse =
(Function.UpdateTable dynamoDbClient dbrequest)
|> Async.RunSynchronously
let statusCode = dbresponse.HttpStatusCode.ToString()
context.Logger.Log(sprintf "DynamoDB response code: %s" statusCode)
APIGatewayProxyResponse(
StatusCode =
if dbresponse.HttpStatusCode = HttpStatusCode.OK then
200
else
555)I picked 555 as the error code to return here just to make it different from error codes typically returned which may come from AWS services.
To deploy this the by now usual steps are needed - run dotnet publish to create new deployment assets for the Lambda function and cdk deploy to then deploy the Lambda function and all the related infrastructure.
Note: In the Lambda function set-up in HelloApiStack.fs I added a Timeout parameter when creating the Lambda function - the default timeout is 3 seconds and it turns out this was not always enough time, at least when there was a cold start happening. So the timeout was increased to 10 seconds:
Timeout = Duration.Seconds(10.0),Checking the logs for the deployed Lambda after executing a few requests to the API endpoint, with some extra additions at the end of the path, we can see logs like this:
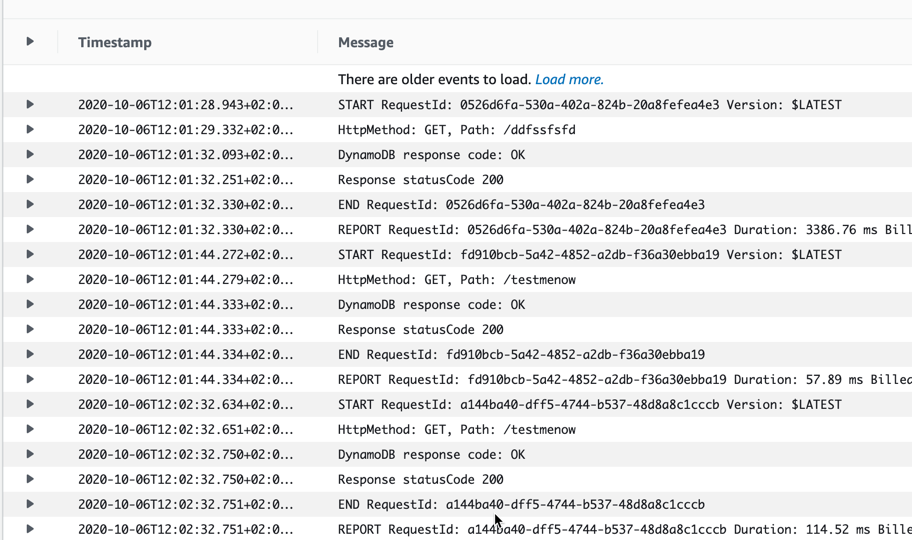
Checking the content of the DynamoDB table that has been created also shows that we see different paths and hits counter being updated:
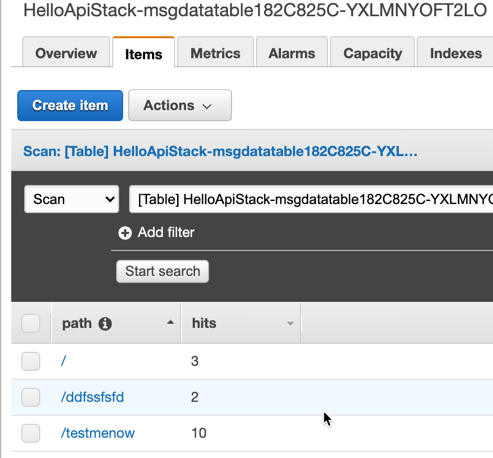
So now we got a Lambda function that processes HTTP API requests via API Gateway and stores info about GET requests in a DynamoDB table. This is so far we will take this implementation in this post.
Summary and final thoughts
I have used the AWS CDK for about a year now, although mainly with Python and Typescript. This was my first venture with .NET and F# with the CDK and I have learned a few things in the process, both about dotnet tools and F# - C# interaction, or how do map these C# thingies to F#?
The experience could be better but was not so bad that I feared it could be, given its object-oriented focus. It does help that F# is a general-purpose language which supports object programming, even though it is labelled as functional first.
It was sad to see that there was not any F# support or examples in the CDK besides the initial templates. In that regard Pulumi is better, which has some explicit support libraries for F#. There are not many examples, but there are a few, like this one. I do like Pulumi, and I will explore that further in F# context at some point later.
I hope that this series of posts have provided some value to you, feel free to comment on what was useful and what could have been better.
Source code
The source code in the articles in this series is in this Github repository: