If you use the principles of infrastructure as code to provision your cloud infrastructure, you get many benefits from it - repeatable, quick, and consistent deployments. You also need to apply discipline in how you update the infrastructure - it has to be through the same infrastructure as code workflow. If anyone modifies the infrastructure through other means, like the AWS Management Console, then all bets are off and you may end up with a mess.
Fortunately, some tools can help to keep your cloud infrastructure tidy. If you use AWS CloudFormation, then you have a feature called Drift Detection which may help you detect when someone changes the infrastructure through other means than CloudFormation. Read further to see how you can use Drift Detection for your benefit.
—READMORE—
This is the first article in a series. We are going to look at drift detection in the AWS Management Console in part 1. In part 2 we then continue with some simple scripts to enable some level of automation. In part 3 we are going to continue further to deploy our drift detection using infrastructure as code and notifications.
I am going to assume that you are familiar with AWS Management Console and you know a bit about AWS CloudFormation and how that is used to provision AWS infrastructure resources. I will also assume that you have familiarity with concepts such as CloudFormation stacks, resources, and templates. If this is new to you, one starting point to get a bit more familiar is to look at AWS own information about the AWS Cloudformation service.
Check drift status in AWS Management Console
If you in the AWS Management Console select the service CloudFormation, you will get a list of all CloudFormation stacks that are currently provisioned in the current AWS account and region.
In my example here I will use a CloudFormation stack called demo-stack, which includes many resources, including some EC2 servers that sit behind an application load balancer. However, the specific details of what is in the stack are not that important.
In the overview of the stack information, two items are of interest to us right now, Drift status and Last drift check time.
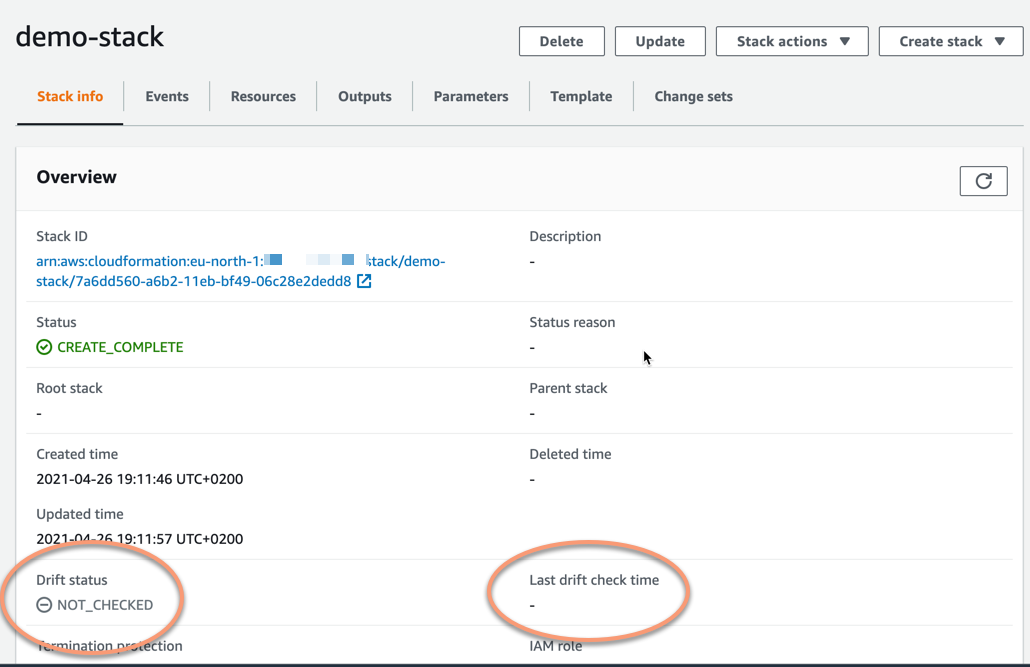
You will notice that the drift status says NOT_CHECKED. This means that there have not been any drift detection checks on this stack at all, so its state regarding any uncontrolled changes is unknown. Hence the last drift check time has no value - it has never been checked.
So let us change that. In the Stack actions menu we can select the option Detect drift. This will start a drift detection check on this stack. This is a small stack and the check is done right away - larger stacks with many resources may take a little bit of time.

You may need to refresh the page to see the update, both Drift status and Last drift check time will have changed. The drift status is now IN_SYNC and last drift check time is set to the time you ran the drift detection.
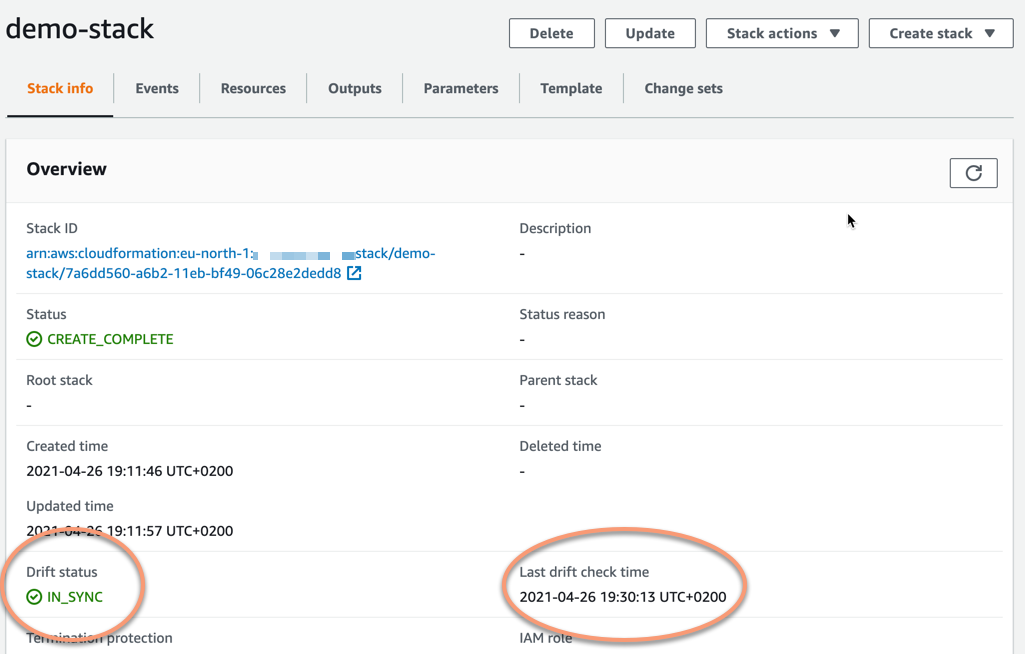
So now we know the last time the state of this CloudFormation stack was in good shape and no uncontrolled changes had been made to its resources.
Let us cause some drift!
Now it is time to put the drift detection to a test! We browse through the different resources available in the stack and pick one that should be an easy and noticeable change in this case. The load balancer that the stack sets up in front of the servers uses a security group towards its targets, the servers.
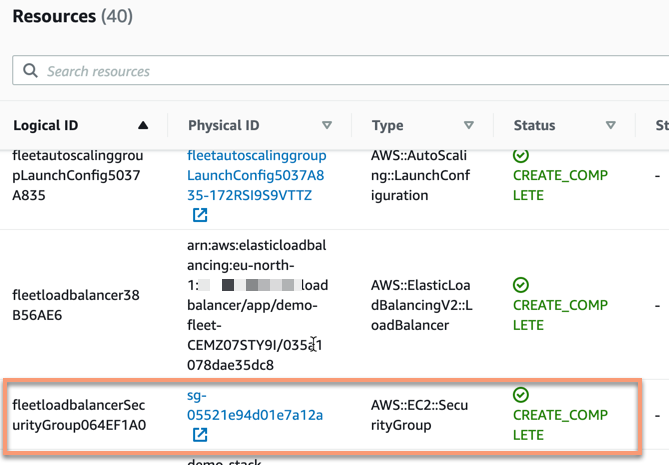
This security group allows traffic to port 8080 and this we are going to change. We can simply go to this security group and change the ingress rule it has for this port to use port 8081 instead. This is of course bad, our solution might not work any longer. Even a small change like this might not be obvious to detect when things start to break down and people might start to complain the solution has stopped working properly.
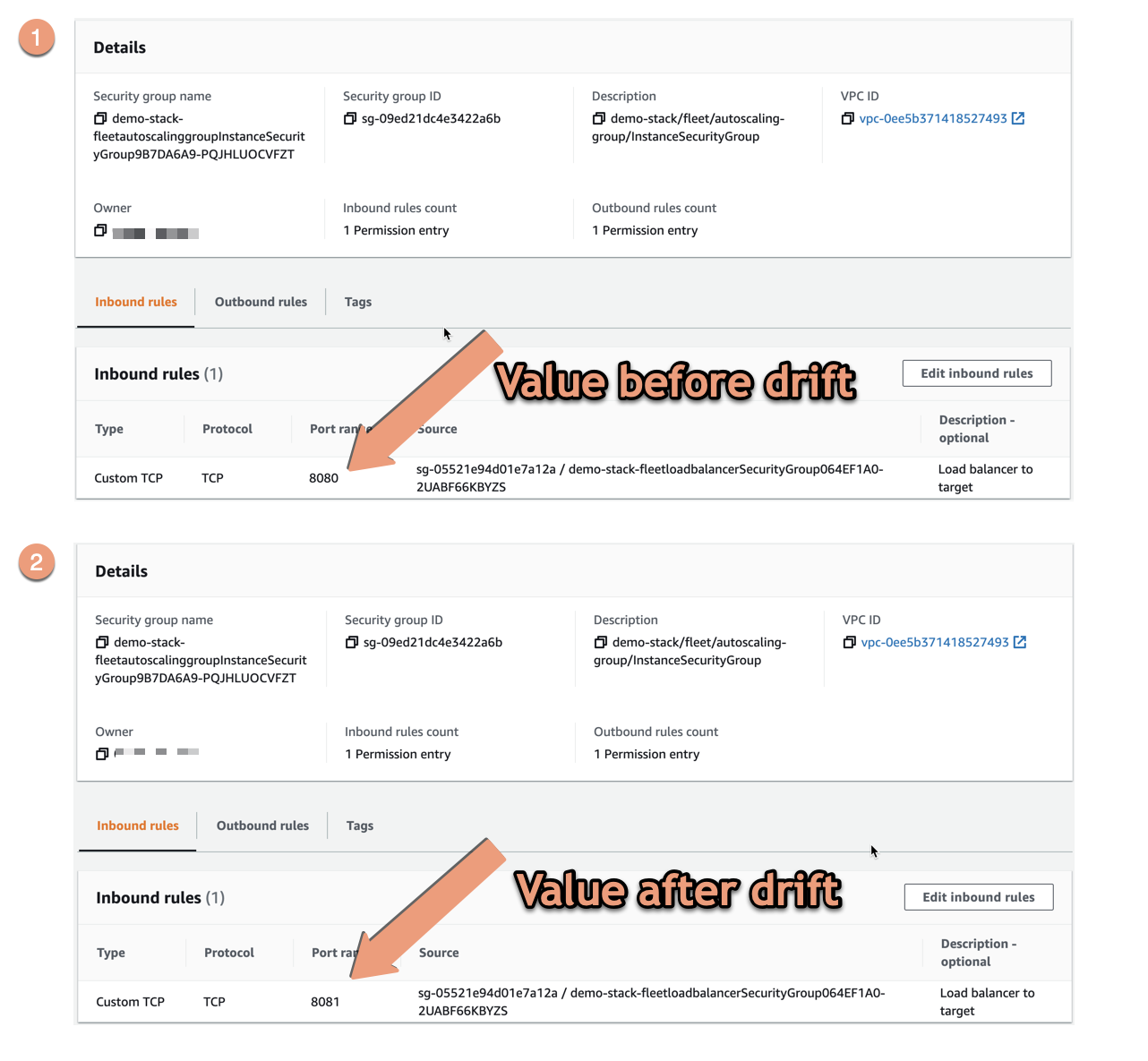
This might not have been a malicious change - someone just tried to make a quick fix for something else, or just made a typo. Either way, we have introduced a discrepancy that may or may not be easy to detect, and which could affect the users of the solution in a bad way.
Next, we will look at detecting a change like this.
Detecting our change
To detect this change we start a drift detection again, from the Stack actions menu and by selecting Detect drift. This will now change the status of our stack. The Drift status is now DRIFTED and the Last drift check time has been updated to this last time we ran the drift detection.
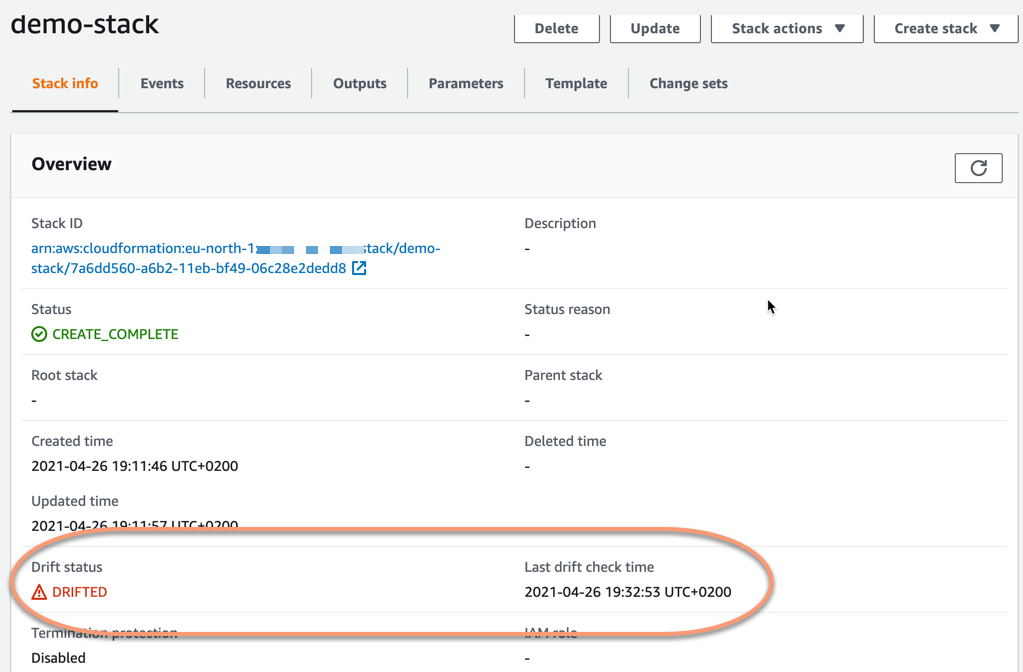
So now we have detected that we have a drift in the stack. We cannot see from the status itself though what has changed. For this, we need to choose to view what changes have been detected. This we can do in the Stack actions menu by choosing View drift results.
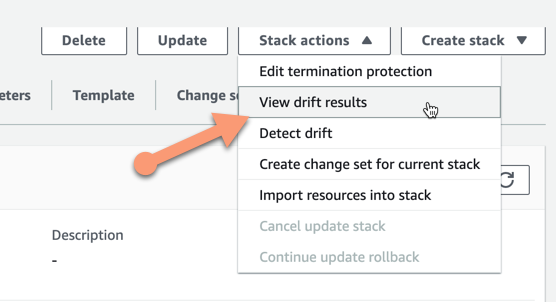
We will see the list of resources in the stack, and in this list, we can see that we have a modified security group - the status shows MODIFIED.
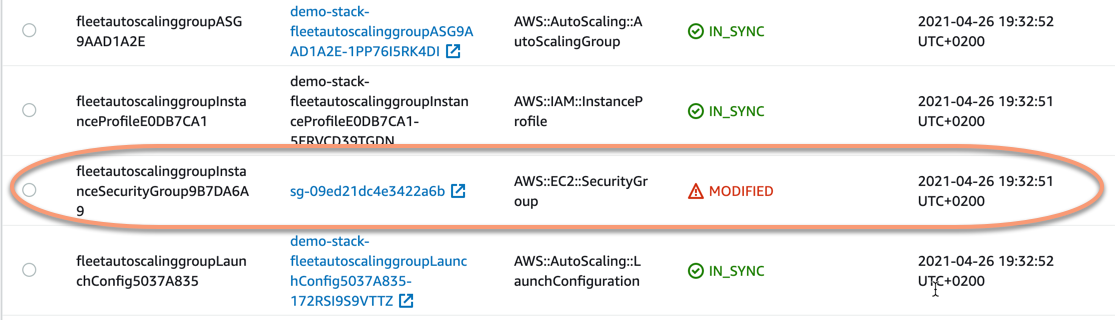
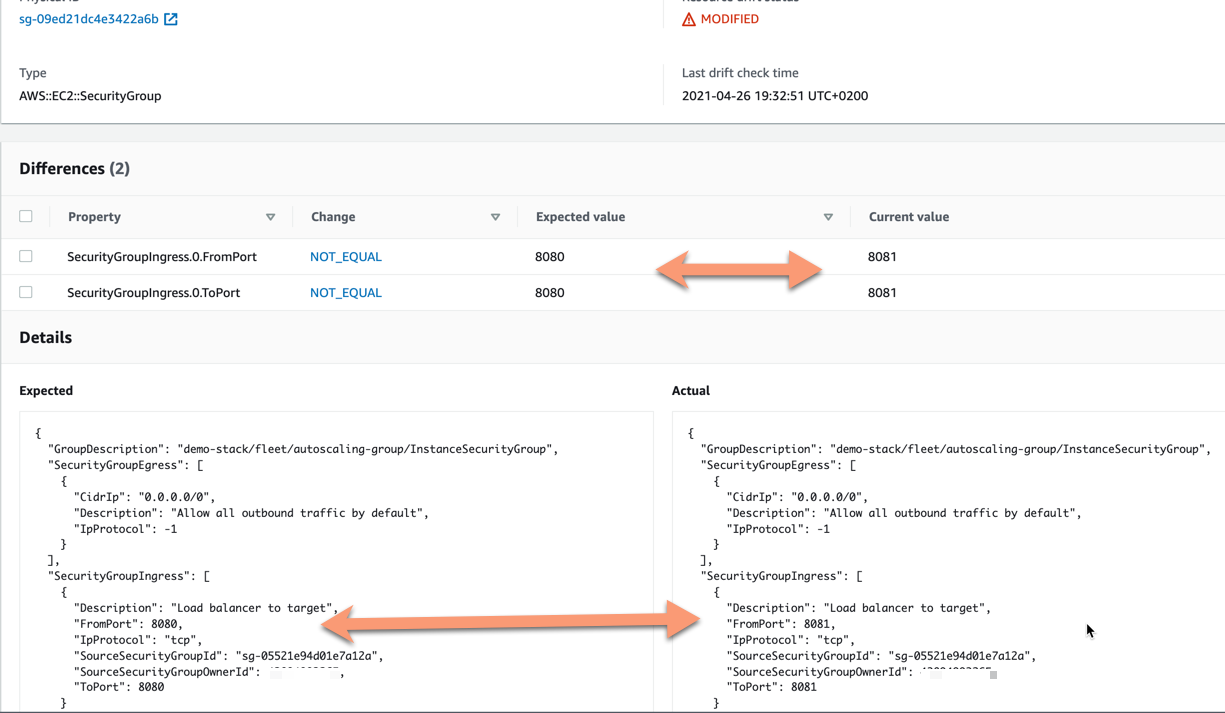
We can expand this modification entry to see more details what has been changed - what are the current values and what are the expected values, i.e. what is in our stack definition.
Here the user interface shows clearly what the change is and what is the expected value and what the actual value is.
What to do about it?
So the next question here is, what to do next? Do we change the modified value back to the expected value, or do we change the CloudFormation stack to match the actual value?
In most cases, the right answer would be to change the value back to its original state. One of the points with using infrastructure-as-code is that you have a version-controlled and readable description of the desired state of the infrastructure. Any changes should be done through a workflow involving this version control state description and then provisioned. So detecting an uncontrolled change like this should be fixed by reverting the change to its original expected value, then if the value was intended to change, do that by updating the version-controlled description of the infrastructure and provision these changes.
Now, in the case where it is just a simple change like this and we are ok with making a manual change to revert it, then that is easy. But if there are changes that we cannot revert that easily (e.g. someone deleted a resource) or we want some automated remediation, then this becomes more complex, unfortunately.
There is no unified and simple fix my stack state operation, besides deleting the stack and recreating it, which in some cases is not what you want to do, especially if the stack contains stateful resources (e.g. databases, persistent disks).
There are multi-step approaches that can be applied with CloudFormation import functionality, which is out of scope for this article.
Other infrastructure-as-code solutions, like Terraform, have different and sometimes easier approaches to drift remediation.
In the end though, regardless of the toolset you use, you do not want drift to happen. Some AWS services have remediation features built-in that will repair some state issues automatically, and using immutable infrastructure will also make it less scary to handle such issues.
Even though remediation may be hard sometimes, the alternative of not detecting uncontrolled changes will be worse. In addition to detecting drift, you should have policies and procedures in place to avoid that such changes will be made in the first place. This may be a cultural and organizational shift, but an important one. Technology and tools alone will not stop things from getting messed up.
Final thoughts
This was in introduction to detecting (uncontrolled) changes to your CloudFormation stacks, which may mess up your infrastructure-as-code deployments. It is a very useful feature, but in practice, it is not that practical to do this via AWS Management Console manually. We want to script and automate these features of course.
In part 2 I will show an approach to write scripts to trigger drift detection and retrieve the results, which may be a bit better than a pure manual check. This will also allow us to check on multiple stacks in one operation, as well as multiple regions. That is relatively simple to do but still requires an explicit action to perform this operation.
In part 3 we will therefore continue to build something that performs a more continuous check and reporting of the drift and which will be deployed as a CloudFormation stack in itself. This can be done in multiple ways - via AWS Lambda, which can be in combination with AWS Config.
I thank you for your time reading this article to the end, and I hope you got some value out of it!