Have you, at least partially, adopted AWS CloudFormation to have better management of your Cloud Infrastructure?
Do you feel that your endeavours with CloudFormation get messy and cumbersome to handle?
Do you want to find a better way to handle cloud infrastructure better, without redoing all your work?
These articles are for you if you answer yes to most of the questions!
In these articles, we will explore how we can improve our management of Cloud Infrastructure in AWS by migrating workflow and tooling from plain AWS CloudFormation and manual steps to using AWS Cloud Development Kit (AWS CDK).
AWS CDK is a newer generation of cloud infrastructure tools from AWS, which builds upon AWS CloudFormation. It can be adopted to make your Cloud Infrastructure management more enjoyable and less cumbersome.
Read the goals and requirements sections below so that you see what to expect. I hope you will get good value from these articles!
Goals
The aim of this series of articles is to explore how go migrate from AWS CloudFormation to AWS Cloud Development Kit (AWS CDK). This includes workflow and tooling aspects.
The focus is on migration, and to preserve existing infrastructure when possible, required and desirable - while still benefit from improvements in AWS CDK tooling. Your infrastructure should be less cumbersome and more enjoyable to maintain and update, and automated as much as possible - possibly more than you may have today.
By the end of this series of articles, we have explored:
- Take an existing AWS CloudFormation solution, preserved, and adapt it to AWS CDK tooling
- Handle both simple and nested CloudFormation stack solutions
- Step-wise reorganisation of CloudFormation stacks to a more CDK-oriented model
- Step-wise replacement of CloudFormation template resources with AWS CDK Constructs
- Adapting CloudFormation-oriented tooling usage to AWS CDK, like cfn-lint, cfn-nag, etc.
- Change and adapt parameterisation of stacks, from CloudFormation model to AWS CDK model
If you want to build green field solutions with AWS CDK, then the series How to become an infrastructure-as-code ninja, using AWS CDK is what you should look at. There will be a bit of overlap between the two series.
If you already know why you want to use AWS CDK and what you need, you can skip to the installation part, or jump to the first example.
Requirements
There are a few requirements for you to get the most of this series.
You should know how to use AWS CloudFormation. You do not need to be an expert, but you should be familiar about wring, reading and deploying CloudFormation stacks.
You need access to an AWS account where you have administrative privileges, temporary or permanent.
You should be able to install software on the computer you use.
You should be able to write and run some small programs with Typescript or Python.
An installation of your programming language of choice, that you can use with AWS CDK. Use a somewhat recent version of each language, such as recent Python version 3, and Typescript version 4).
You also need some basic knowledge of a few common AWS services, like IAM, EC2.
The AWS CDK supports multiple programming languages. There will be sample code using two languages in this article series:
- Typescript - this is the native language of AWS CDK
- Python - a common choice of language for many scripting tasks, and supported by AWS CDK
There are other languages supported as well, but for now we use these two.
Later updates of this article series are planned to include additional language examples.
AWS CloudFormation vs AWS Cloud Development Kit
So why would or should you consider migrating to AWS CDK from AWS CloudFormation?
What is the value proposition?
There are a few areas which may provide benefits:
- It is easier to build and use interfaces at a suitable level for a use case, rather than being forced into low-level details for pretty much everything with CloudFormation.
- Better default tooling. AWS CDK has a command-line tool which makes it rather easy to deploy, update, check for changes and delete Cloud infrastructure stacks. The default tooling using either AWS CLI or AWS Tools for PowerShell frankly sucks in comparison.
- Better language tooling. There are more and better tools to support writing (complex) things in programming languages, than YAML or JSON.
- Better organisational capabilities in AWS CDK, what to put where and how and when to parameterise the infrastructure.
There are also drawbacks that come with AWS CDK:
- Additional complexity. While CloudFormation YAML/JSON suck to build abstractions, it has the benefit that it is more clear what infrastructure will be generated at a micro-level. You are a bit more at risk shooting yourself in the foot with bad code in AWS CDK.
- Dependency on Node.js, and NPM. Regardless of which programming language you use, you will need to have a Node.js runtime installed from NPM. This is for the command-line tool.
- Leaky abstractions. AWS CDK uses AWS CloudFormation under the hood, and in some areas that show through. This means you need to understand both AWS CDK and some CloudFormation for some scenarios.
You can essentially use AWS CDK command-line tool to make a better workflow and take advantage of benefits 2 and 4 and still write your infrastructure with CloudFormation only, or you can go all-in on programming language code, or somewhere in between. We will explore different options as part of the migration efforts we will look at.
AWS CDK Installation
The first step to get started with using AWS CDK to migrate from AWS CloudFormation is to install AWS CDK command-line tool. The tool itself is written in Typescript, and uses the Node.js runtime.
If you already have Node.js installed on your computer, then that is a great start! You can go on with the actual CDK installation below. If you do not have Node.js you will need to install its runtime.
You can download the Node.js runtime from the Node.js website. The long-term support (LTS) release is the recommended version to use, but you can use some older versions and newer versions as well.
You can also install Node.js via different package managers, depending on the computer environment you are working with. See the Node.js package manager page for suggestions. You can also download tools there to manage multiple separate versions of Node.js, if needed.
If you have Node.js installed, you can install the AWS CDK command-line tool. For any of the supported programming languages that are not Typescript, you want to do a global install of the command-line tool (not a project-local install), since you would likely not use Node.js in the cloud infrastructure project itself. If you intend to use Typescript as a language, both a global install and a project-local install would be valid options.
To install the AWS CDK command-line tool globally, run the following command in a shell:
npm install -g aws-cdk
The command npm is the Node.js package manager, which installs the package aws-cdk. It will install the latest version of AWS CDK, which is 2.10.0 at the time of writing this. It is the major version that I would recommend to use if you are new to AWS CDK and are just starting out. If you have AWS CDK version 1, the code will be slightly different, but will work as well. In this context, the differences are small.
After installation of the aws-cdk package, you will have the command-line tool cdk available. You can test that it is available and with the expected version by running it with the version argument:
❯ cdk version
2.10.0 (build e5b301f)If you have that in place, we are now ready to get started with the actual first migration project sample! Time to get our hands dirty, and our cloud infrastructure more tidy!
First sample migration
Since our goal if to migrate existing CloudFormation infrastructure to AWS CDK, we will of course start with some CloudFormation infrastructure. I will show our steps here with a sample CloudFormation template from AWS. You are also free to pick your own one to use. I have a few suggestions for what to pick at this point in time if you bring your own template:
- It should be a template which creates only a single stack, no nested templates and stacks.
- You can use AWS SAM templates, although I would suggest plain CloudFormation templates initially.
- It should only have a handful of parameters at most, preferably not over 4-5, but not a strict rule.
- You should be ok with deploying that CloudFormation stack first prior to starting the AWS CDK work, or already have that deployed in an environment (preferably non-production).
- You can use either YAML or JSON format for your CloudFormation template, both work fine
If you do not have your own template to work with, we will start by using this sample template from AWS: https://s3.eu-west-1.amazonaws.com/cloudformation-templates-eu-west-1/EC2InstanceWithSecurityGroupSample.template
This CloudFormation template will create an EC2 instance with an associated security group. It requires an existing KeyPair name for SSH access, for which there are better alternatives nowadays.
Using this template will insure some cost as well, for as long as the EC2 instance is running. This cost should be small, as long as you remember to clean it up afterwards.
The exact content of the CloudFormation template is not so important, just that we start with a relatively simple template at first. If you use your own template, you can, of course, decide yourself whether it should be cleaned up.
Initalize the project
Before writing any code for our CloudFormation to AWS CDK migration, we should initialise our AWS CDK project to get started.
In a command-line shell, create a directory to contain the project, and go to that directory:
mkdir my-cfn-cdk-migration
cd my-cfn-cdk-migrationIn this directory, we will use the CDK command-line tool to initialise a project for Typescript. We use the init app sub-command with the —language option set to either typescript, python, or go.
❯ cdk init app --language=typescriptApplying project template app for typescript
❯ cdk init app --language=pythonApplying project template app for python
Each initialisation will create slightly different files, depending on the language. But before looking at any of these files, let us save the CloudFormation template we choose to use in our project file structure. We can create a directory named cfn and store the template in there as sample.template. If you use Linux, macOS, or Linux on Windows, you could run the command below to use the sample template mentioned:
❯ mkdir cfn
❯ curl --output cfn/sample.template <https://s3.eu-west-1.amazonaws.com/cloudformation-templates-eu-west-1/EC2InstanceWithSecurityGroupSample.template>For each of the languages chosen, we will initially focus on just a single file to write the AWS CDK code to use our existing CloudFormation template (cfn/sample.template):
- Typescript: bin/my-cfn-cdk-migration.ts
- Python: app.py
We will just start with the code, and then explain the details step by step, along with testing how that works. You see both Typescript and Python code below, and you will find them reasonably similar. The code comprises essentially five areas:
- Import of modules and class/structure definitions
- Environment setup
- AWS CDK App and Stack initialisation
- Inclusion of CloudFormation template
- Synthesize CloudFormation
#!/usr/bin/env node
import 'source-map-support/register';
import * as path from 'path';
import { App, Environment, Stack } from 'aws-cdk-lib';
import { CfnInclude } from 'aws-cdk-lib/cloudformation-include';
const env: Environment = {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
};
const stackName = 'mystack';
const app = new App();
const stack = new Stack(app, 'wrapper-stack', { env, stackName });
new CfnInclude(stack, 'included-template', {
templateFile: path.join(process.cwd(), 'cfn', 'sample.template'),
});
app.synth();#!/usr/bin/env python3
import os
from aws_cdk import (
App,
Environment,
Stack
)
from aws_cdk.cloudformation_include import CfnInclude
env = Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION'))
stack_name = 'mystack'
app = App()
stack = Stack(app, 'wrapper-stack', env=env, stack_name=stack_name)
CfnInclude(stack, 'included-template', template_file=os.path.join(os.getcwd(), 'cfn', 'sample.template'))
app.synth()Let us start with the App and Stack parts. When we use the AWS CDK, all infrastructure we manage as some kind of larger scale unit is grouped into an App. This the top-level container, which contains everything that you can provision in the project or solution you are working with.
Each App may comprise one or more stacks. A Stack is a collection of AWS resources that you provide and manage as a unit. It could be your whole solution, or it could be just one part of a solution. An AWS CDK stack maps 1-to-1 with a CloudFormation stack.
For Stacks, we can in AWS CDK attach Constructs, which are a logical grouping of Resources, which are the same type of resources that you represent in CloudFormation as well. In the code, we have a CfnInclude construct, which performs the inclusion of a CloudFormation template, a Stack and an App in AWS CDK. The only parameter here so far is to point to the CloudFormation template in our project. This is the stuff to include into the AWS CDK App and the related stack.
We also have the concept of an Environment, which in AWS CDK context is a combination of AWS account and AWS region. A CDK App can target multiple accounts and/or multiple regions within the same app.
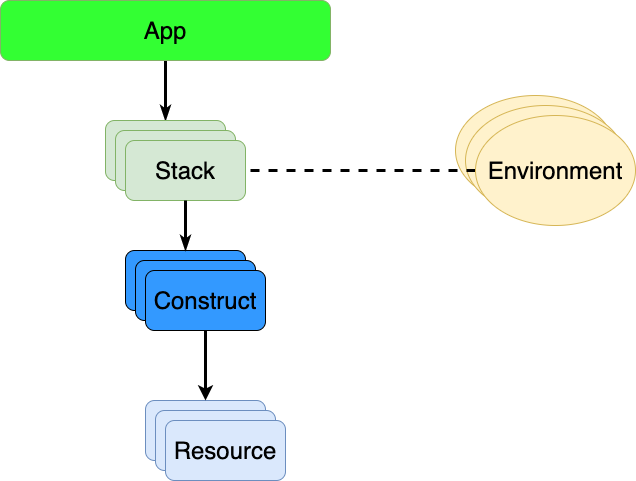
The environment setup in the code is essentially using two environment variables that the AWS CDK has built in, which captures whatever is the current AWS account id and AWS region, based on the currently active AWS credentials that you use. CDK_DEFAULT_ACCOUNT and CDK_DEFAULT_REGION are the names of these environment variables.
So this approach assumes you have done your work to activate an AWS credentials profile, or set environment variables for credentials or equivalent, and then the CDK code will get the account and region info from that. This can be fine for development environments, but in particular with production environments, you would want some additional guardrails. For now, that is not our focus, though.
The final area is to synthesize to CloudFormation. This the task of the code app.synth(). It generates the underlying CloudFormation.
You can put the code into the program files mentioned above, app.py or bin/my-cfn-cdk-migration.ts.
You can see the hierarchy shown in the picture in the code itself. The App itself is just created, we have an object for that. The line with the Stack creation adds a reference to the App, plus a name which is the name of the stack in this case. After that, there are additional parameters for the environment.
The CfnInclude creation follows the same pattern. It adds a reference to the Stack, plus a name. After that, there are additional parameters, in this case, a reference to the CloudFormation template file.
All logical resource groupings in AWS CDK follow the same pattern - a reference to the parent in a hierarchy and a name. With a Stack, the name is the same as the name of the CloudFormation stack in AWS. Below the stack level, into construct territory, there is less concern with having a specific name. However, a name will need to be unique under a specific parent in the hierarchy.
Note: If you have not already deployed sample.template CloudFormation to an environment without using the AWS CDK, now is the time to do this. We will assume below that the CloudFormation template already has been deployed, and the work we do will be in the light of changes to do when we have an existing (non-CDK) infrastructure already in place.
So deploy it, if you need to. We will wait…
… alright, done now? Great!
Also, note down the name of the CloudFormation stack you have deployed. This is important. If the name is not the same as the name set in the Stack object in the code, change the name of the stack in the code to match the deployed stack.
The AWS CDK initialisation we did before with the cdk init command behaved slightly differently depending on the language we choose to use. For Typescript, the cdk init performed the needed package installation. For Python, we have a bit more to do:
For Python, activate the virtual environment that cdk init created for you. In Linux och macOS, run
source ./.venv/bin/activate
and in Windows
.venv\Scripts\activate.bat
To activate the virtual environment that has been set up. Then run the package installation:
pip3 install -r requirements.txt
This will install the required AWS CDK packages. We have now:
- An initialised AWS CDK project
- Required AWS CDK packages installed
- An AWS CDK app wrapper around our existing CloudFormation template
Now it is time to look closer to the code and actually check that this AWS CDK app actually works!
Checking for CloudFormation changes
Since the plan here is to do a migration from an existing CloudFormation infrastructure deployment to use AWS CDK, we want really everything to be the same when we use AWS CDK. No messing around with our existing infrastructure!
So what we want first is to check that what we have with AWS CDK matches what we have already deployed before. We can use the AWS CDK command-line tool for this. All commands should be executed in the same directory as the cdk.json file is in, which is the root directory of our project.
Note: you have to have your AWS credentials in place when you run the AWS CDK commands, since you will work towards the target AWS environment. It does not matter whether you set AWS regular environment variables (e.g. AWS_SECRET_ACCESS_KEY, AWS_ACCESS_KEY_ID, AWS_DEFAULT_REGION, etc) or use AWS credentials profiles. If you use AWS credentials profiles, add a –profile profile_name to each command line to specify the name of the profile, if the profile name is not default.
The AWS CDK command-line tool has a sub-command diff, which can compare the under-the-hood generated CloudFormation with what is actually deployed. If you run the cdk diff command and run it with the sample template we have, and the stack name is correct, and you have set the AWS credentials for your environment, see the following output (expect probably to wait 10-15 seconds):
❯ cdk diff
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
Stack mystack
Parameters
[+] Parameter BootstrapVersion BootstrapVersion: {"Type":"AWS::SSM::Parameter::Value<String>","Default":"/cdk-bootstrap/hnb659fds/version","Description":"Version of the CDK Bootstrap resources in this environment, automatically retrieved from SSM Parameter Store. [cdk:skip]"}
Other Changes
[+] Unknown Rules: {"CheckBootstrapVersion":{"Assertions":[{"Assert":{"Fn::Not":[{"Fn::Contains":[["1","2","3","4","5"],{"Ref":"BootstrapVersion"}]}]},"AssertDescription":"CDK bootstrap stack version 6 required. Please run 'cdk bootstrap' with a recent version of the CDK CLI."}]}}If you use your own CloudFormation template and stack, the FindInMap warnings will probably not be the same, since these depend on the specific CloudFormation template in use. We can ignore these warnings for now as well. It is only a potential optimisation that could be done.
There are two resources that are shown with plus signs, so if we deploy the stack in the AWS CDK App, these would be added to the stack. There are no resources with minus signs in front of them, which means there are no resources removed. The differences are shown at the CloudFormation level, so it is beneficial to know a bit of CloudFormation for this type of operation.
What are these added entries?
The first entry is an added CloudFormation template parameter, called BootstrapVersion. The value will automatically be retrieved from this parameter in Parameter Store when CloudFormation deploys the stack.
The second entry is a CloudFormation rule, which performs validation of BootstrapVersion. Have a recent enough bootstrap done, otherwise the stack deployment will fail.
We will cover the bootstrapping in the next section below. What we can see here, though, is that, except for this bootstrapping part, there are no changes. As long as we can accept this bootstrap parameter and added rule validation, it will be all the same.
All AWS CDK stacks will have this type of parameter and rule. It is part of the baseline you can expect.
You can see the generated CloudFormation template from AWS CDK by running the cdk synth command. The output should be identical to the original CloudFormation template, with the addition of the parameter and rule for BootstrapVersion.
What is bootstrapping?
To actually deploy stacks in an AWS CDK App, you need to bootstrap the target environment. The bootstrap process will create an S3 bucket, and at least some IAM roles, and the BootstrapVersion parameter in Parameter Store.
The S3 bucket is used to upload things to deploy basically. If you use plain CloudFormation, you know that for many cases you will need to upload CloudFormation template files to some S3 bucket first, before it can be used.
The AWS CDK bootstrap creates such a bucket for you and handles the uploads and references to uploaded data under the hood for you, so you do not need to worry about it. This simplifies workflows with AWS CDK.
The bootstrap process is a onetime task for each target environment (account plus region combination). You do that once, and then do not have to do that again - only if there were some changes in prerequisites for the environment, you may need to perform an update at some point. For all normal interactions, though, once you have bootstrapped you are good to do not have to think about it again.
To bootstrap the current target environment, you simply execute the command cdk bootstrap. It will deploy a CloudFormation stack with the resources that belong to the bootstrapping, with a (default) name of the stack as CDKToolkit.
Please run cdk bootstrap in your target environment. It is needed for us to perform any changes/updates on our target stack. If you prefer not to do any updates, just read about the rest. But in order to perform actual changes with AWS CDK, you need to bootstrap first.
Deploy update to stack
Once we have bootstrapped our target environment, we can deploy this update to our existing stack. This is also something to think about whether you want to adopt AWS CDK as a wrapper around your existing CloudFormation infrastructure. AWS CDK will add this bootstrap information, as well as additional metadata to the CloudFormation stacks it deploys.
You can keep working with your existing CloudFormation templates and edit those. In addition, you also have an AWS CDK wrapper code around your CloudFormation templates, plus use the AWS DK command-line tool. You will get bootstrap and metadata added to the stacks if you choose to use AWS CDK commands for deployment and management. Mixing that with other deployment methods for CloudFormation stacks may not be optimal.
So a strong recommendation here is to experiment with AWS CDK command-line tool and see if you think it brings value, compared to what you use today.
That being said, let us look at deploying these changes to the stack. To perform the update to the stack, we can simply run the cdk deploy command. Since we only have a single stack in the AWS CDK app, it will simply deploy that stack using the current AWS credentials.
❯ cdk deploy
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
✨ Synthesis time: 10.36s
mystack: deploying...
[0%] start: Publishing 4dcb1b0af0f37ffd3820e5c6c660615d743078920ae05497462670220e892d74:current_account-eu-west-1
[100%] success: Published 4dcb1b0af0f37ffd3820e5c6c660615d743078920ae05497462670220e892d74:current_account-eu-west-1
mystack: creating CloudFormation changeset...
✅ mystack
✨ Deployment time: 25.58s
Outputs:
mystack.AZ = eu-west-1b
mystack.InstanceId = i-08ec677b2ca564471
mystack.PublicDNS = ec2-63-35-162-187.eu-west-1.compute.amazonaws.com
mystack.PublicIP = 63.35.162.187
Stack ARN:
arn:aws:cloudformation:eu-west-1:123456789012:stack/mystack/ffc6cc30-7e98-11ec-8c08-0244eda65617
✨ Total time: 35.94sAfter executing the deployment of the stack, you can run the cdk diff command again. You will see that there are no differences between the generated output from the AWS CDK app and the actual deployed stack.
❯ cdk diff
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
Stack mystack
There were no differencesThe stack generated from our AWS CDK app is now the same as what we have deployed. No real changes, just extra information that AWS CDK itself requires. Next step is to do some real changes, and also look at handling parameters we send in during stack creation/update.
Updating parameters and stacks
Let us now look at how we can update our stacks using AWS CDK. We start with changing the existing parameters. You noticed that by default, we were not required to re-enter any existing parameters if we updated the existing stack. This is normal behaviour for CloudFormation as well.
However, if we want to change an existing parameter when we deploy a stack, we can add that on the command-line, using the —parameters option. In our sample template, we have a parameter InstanceType, which specifies what type of EC2 instance we shall deploy. By default, it deploys a t2.small instance. We can change that to a “t2.micro” instance, for example, by changing the parameter on the command-line when we deploy it. We need to specify the name of the stack and the name of the parameter. Remember that an AWS CDK app can contain multiple stacks!
❯ cdk deploy --parameters mystack:InstanceType=t2.micro
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
✨ Synthesis time: 10.65s
mystack: deploying...
[0%] start: Publishing 4dcb1b0af0f37ffd3820e5c6c660615d743078920ae05497462670220e892d74:current_account-eu-west-1
[100%] success: Published 4dcb1b0af0f37ffd3820e5c6c660615d743078920ae05497462670220e892d74:current_account-eu-west-1
mystack: creating CloudFormation changeset...
✅ mystack
✨ Deployment time: 114.52s
Outputs:
mystack.AZ = eu-west-1b
mystack.InstanceId = i-08ec677b2ca564471
mystack.PublicDNS = ec2-34-245-79-51.eu-west-1.compute.amazonaws.com
mystack.PublicIP = 34.245.79.51
Stack ARN:
arn:aws:cloudformation:eu-west-1:123456789012:stack/mystack/ffc6cc30-7e98-11ec-8c08-0244eda65617
✨ Total time: 125.17sIf we try to run cdk diff using —parameters option, that will not work through. The cdk diff command does not support —parameters, at least not at the time of writing this. Is there a way to overcome this issue?
AWS CDK only provides support for CloudFormation parameters to be compatible with CloudFormation. You can resolve values when you run the code, and when you deploy the generated stacks, through different means.
We can include the parameters directly in the CfnInclude construct creation. How we get these parameters are up to us - from command-line, from some other file, hard-coded, a database or anything else we can do with some code. In our example here, I have simply added a variable in the code with the desired value.
#!/usr/bin/env node
import 'source-map-support/register';
import * as path from 'path';
import { App, Environment, Stack } from 'aws-cdk-lib';
import { CfnInclude } from 'aws-cdk-lib/cloudformation-include';
const env: Environment = {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
};
const stackName = 'mystack';
const app = new App();
const stack = new Stack(app, 'wrapper-stack', { env, stackName });
const instanceType = 't2.small';
new CfnInclude(stack, 'included-template', {
templateFile: path.join(process.cwd(), 'cfn', 'sample.template'),
parameters: {
InstanceType: instanceType,
},
});
app.synth();#!/usr/bin/env python3
import os
from aws_cdk import (
App,
Environment,
Stack
)
from aws_cdk.cloudformation_include import CfnInclude
env = Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION'))
stack_name = 'mystack'
app = App()
stack = Stack(app, 'wrapper-stack', env=env, stack_name=stack_name)
instance_type = 't2.small'
CfnInclude(stack,
'included-template',
template_file=os.path.join(os.getcwd(), 'cfn', 'sample.template'),
parameters={
'InstanceType' : instance_type,
})
app.synth()If you run cdk diff after these code changes, you will notice something interesting! The parameter itself is removed completely from the generated CloudFormation, and the actual instance type value is included directly instead!
❯ cdk diff
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
Stack mystack
Parameters
[-] Parameter InstanceType: {"Type":"String","Default":"t2.small","AllowedValues":["t1.micro","t2.nano","t2.micro","t2.small","t2.medium","t2.large","m1.small","m1.medium","m1.large","m1.xlarge","m2.xlarge","m2.2xlarge","m2.4xlarge","m3.medium","m3.large","m3.xlarge","m3.2xlarge","m4.large","m4.xlarge","m4.2xlarge","m4.4xlarge","m4.10xlarge","c1.medium","c1.xlarge","c3.large","c3.xlarge","c3.2xlarge","c3.4xlarge","c3.8xlarge","c4.large","c4.xlarge","c4.2xlarge","c4.4xlarge","c4.8xlarge","g2.2xlarge","g2.8xlarge","r3.large","r3.xlarge","r3.2xlarge","r3.4xlarge","r3.8xlarge","i2.xlarge","i2.2xlarge","i2.4xlarge","i2.8xlarge","d2.xlarge","d2.2xlarge","d2.4xlarge","d2.8xlarge","hi1.4xlarge","hs1.8xlarge","cr1.8xlarge","cc2.8xlarge","cg1.4xlarge"],"ConstraintDescription":"must be a valid EC2 instance type.","Description":"WebServer EC2 instance type"}
Resources
[~] AWS::EC2::Instance included-template/EC2Instance EC2Instance replace
├─ [~] ImageId (requires replacement)
│ └─ [~] .Fn::FindInMap:
│ └─ @@ -6,9 +6,7 @@
│ [ ] {
│ [ ] "Fn::FindInMap": [
│ [ ] "AWSInstanceType2Arch",
│ [-] {
│ [-] "Ref": "InstanceType"
│ [-] },
│ [+] "t2.small",
│ [ ] "Arch"
│ [ ] ]
│ [ ] }
└─ [~] InstanceType (may cause replacement)
└─ @@ -1,3 +1,1 @@
[-] {
[-] "Ref": "InstanceType"
[-] }
[+] "t2.small"The reason for this is that AWS CDK can determine the value to set for InstanceType already at the time you run the code. There is no need to have a parameter at all, so the parameter from the original CloudFormation template is eliminated. Run cdk synth and look at the generated CloudFormation output where there is no InstanceType parameter anymore.
This is a different mental model compared to using CloudFormation. AWS CDK resolves everything it can when running the code, and the other things it does later. This happens under the hood to some extent. An AWS CDK app may contain all stacks for all environments. The differences are expressed in the code.
It is, of course, possible to not follow that model. AWS CDK tries to facilitate to use this approach, but does not enforce it. You can keep your existing way of working with parameters if you want to keep using AWS CloudFormation templates as your primary source for infrastructure and only use AWS CDK command-line tool to make the workflow a bit more convenient. If you want to adopt using AWS CDK for the infrastructure, then you should also adapt your approach to handling parameterisation.
You can now run cdk deploy to deploy these changes. AWS CDK will perform the update, which will take a few minutes to complete, since it will replace the EC2 instance with a new one.
Another parameter update - security changes
In the same way that we updated InstanceType in our sample template, we can also update the SSHLocation parameter. We simply add that in the same way in the code and set the default value 0.0.0.0/0 in the code.
#!/usr/bin/env node
import 'source-map-support/register';
import * as path from 'path';
import { App, Environment, Stack } from 'aws-cdk-lib';
import { CfnInclude } from 'aws-cdk-lib/cloudformation-include';
const env: Environment = {
account: process.env.CDK_DEFAULT_ACCOUNT,
region: process.env.CDK_DEFAULT_REGION,
};
const stackName = 'mystack';
const app = new App();
const stack = new Stack(app, 'wrapper-stack', { env, stackName });
const instanceType = 't2.small';
const sshLocation = '0.0.0.0/0';
new CfnInclude(stack, 'included-template', {
templateFile: path.join(process.cwd(), 'cfn', 'sample.template'),
parameters: {
InstanceType: instanceType,
SSHLocation: sshLocation,
},
});
app.synth();#!/usr/bin/env python3
import os
from aws_cdk import (
App,
Environment,
Stack
)
from aws_cdk.cloudformation_include import CfnInclude
env = Environment(account=os.getenv('CDK_DEFAULT_ACCOUNT'), region=os.getenv('CDK_DEFAULT_REGION'))
stack_name = 'mystack'
app = App()
stack = Stack(app, 'wrapper-stack', env=env, stack_name=stack_name)
instance_type = 't2.small'
ssh_location = '0.0.0.0/0'
CfnInclude(stack,
'included-template',
template_file=os.path.join(os.getcwd(), 'cfn', 'sample.template'),
parameters={
'InstanceType' : instance_type,
'SSHLocation' : ssh_location
})
app.synth()If you run a cdk diff on the code, and you use the sample template, you will see an output like this:
❯ cdk diff
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
Stack mystack
Security Group Changes
┌───┬────────────────────────────────────────────────────┬─────┬──────────┬─────────────────┐
│ │ Group │ Dir │ Protocol │ Peer │
├───┼────────────────────────────────────────────────────┼─────┼──────────┼─────────────────┤
│ - │ ${included-template/InstanceSecurityGroup.GroupId} │ In │ TCP 22 │ ${SSHLocation} │
├───┼────────────────────────────────────────────────────┼─────┼──────────┼─────────────────┤
│ + │ ${included-template/InstanceSecurityGroup.GroupId} │ In │ TCP 22 │ Everyone (IPv4) │
└───┴────────────────────────────────────────────────────┴─────┴──────────┴─────────────────┘
(NOTE: There may be security-related changes not in this list. See https://github.com/aws/aws-cdk/issues/1299)
Parameters
[-] Parameter SSHLocation: {"Type":"String","Default":"0.0.0.0/0","AllowedPattern":"(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})","ConstraintDescription":"must be a valid IP CIDR range of the form x.x.x.x/x.","Description":"The IP address range that can be used to SSH to the EC2 instances","MaxLength":"18","MinLength":"9"}
Resources
[~] AWS::EC2::SecurityGroup included-template/InstanceSecurityGroup InstanceSecurityGroup
└─ [~] SecurityGroupIngress
└─ @@ -1,8 +1,6 @@
[ ] [
[ ] {
[-] "CidrIp": {
[-] "Ref": "SSHLocation"
[-] },
[+] "CidrIp": "0.0.0.0/0",
[ ] "FromPort": 22,
[ ] "IpProtocol": "tcp",
[ ] "ToPort": 22A security group rule has the source value changed from a variable to an explicit value 0.0.0.0/0. It is the same value provided via the parameter before, but now it is set already when the code runs.
To have the actual value in the template is better, since you can check the value with security tooling before it is deployed. So this is an advantage of the AWS CDK model with trying to resolve parameterisation as early as possible.
If you run cdk deploy to deploy these changes, you will also see a change in the deployment workflow. You will get a prompt asking about security group changes, so that you can do an approval that these changes will be performed.
❯ cdk deploy
[Info at /mystack/included-template/$Mappings/AWSInstanceType2Arch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSInstanceType2NATArch] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
[Info at /mystack/included-template/$Mappings/AWSRegionArch2AMI] Consider making this CfnMapping a lazy mapping by providing `lazy: true`: either no findInMap was called or every findInMap could be immediately resolved without using Fn::FindInMap
✨ Synthesis time: 10.72s
This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening).
Please confirm you intend to make the following modifications:
Security Group Changes
┌───┬────────────────────────────────────────────────────┬─────┬──────────┬─────────────────┐
│ │ Group │ Dir │ Protocol │ Peer │
├───┼────────────────────────────────────────────────────┼─────┼──────────┼─────────────────┤
│ - │ ${included-template/InstanceSecurityGroup.GroupId} │ In │ TCP 22 │ ${SSHLocation} │
├───┼────────────────────────────────────────────────────┼─────┼──────────┼─────────────────┤
│ + │ ${included-template/InstanceSecurityGroup.GroupId} │ In │ TCP 22 │ Everyone (IPv4) │
└───┴────────────────────────────────────────────────────┴─────┴──────────┴─────────────────┘
(NOTE: There may be security-related changes not in this list. See https://github.com/aws/aws-cdk/issues/1299)
Do you wish to deploy these changes (y/n)? y
mystack: deploying...
[0%] start: Publishing 573ae98f43ba74567ae46ffe8df6d11132f8ef444d61e22ee031b763e4562c2b:069901141591-eu-west-1
[100%] success: Published 573ae98f43ba74567ae46ffe8df6d11132f8ef444d61e22ee031b763e4562c2b:069901141591-eu-west-1
mystack: creating CloudFormation changeset...
✅ mystack (no changes)
✨ Deployment time: 9.83s
Outputs:
mystack.AZ = eu-west-1b
mystack.InstanceId = i-08ec677b2ca564471
mystack.PublicDNS = ec2-34-247-191-237.eu-west-1.compute.amazonaws.com
mystack.PublicIP = 34.247.191.237
Stack ARN:
arn:aws:cloudformation:eu-west-1:123456789012:stack/mystack/ffc6cc30-7e98-11ec-8c08-0244eda65617
✨ Total time: 20.55sThe default check is to prompt you for confirmation if it needs additional access or permissions from before. You can set this behaviour with the —require-approval option. It can be set to either never, any-change, or to broadening. The default is broadening.
This is a feature that I think is valuable and a minimum sanity check. This is something that adds value if you don’t have similar tools before.
Wrapping up
We have the following goals in this series of articles:
- Take an existing AWS CloudFormation solution, preserved, and adapt it to AWS CDK tooling
- Handle both simple and nested CloudFormation stack solutions
- Step-wise reorganisation of CloudFormation stacks to a more CDK-oriented model
- Step-wise replacement of CloudFormation template resources with AWS CDK Constructs
- Adapting CloudFormation-oriented tooling usage to AWS CDK, like cfn-lint, cfn-nag, etc.
- Change and adapt parameterisation of stacks, from CloudFormation model to AWS CDK model
We have started with the first point in this list of goals and have partially done point two as well. Finally, we have also started with the sixth point to change and adapt the parameterisation of stacks.
This is as far as we will go in this article, and in the next article we will dig further into the template and stack handling with nested CloudFormation templates and stacks.
Before signing off in this article, I highly recommend that if you have created new infrastructure with the sample template provided, you clean it up and remove it. This is pretty straightforward with the AWS CDK command-line tool, you simply run the cdk destroy command. It will prompt you to confirm that you want to delete the stack, and then delete it, if you answer yes.
❯ cdk destroy
Are you sure you want to delete: mystack (y/n)? y
mystack: destroying...
✅ mystack: destroyedDo not forget that!