Hello all!
Welcome to the next issue of the Tidy Cloud AWS bulletin! In this issue, there are a few software projects from AWS that may be of interest, a very nice book about software design, some wise words from the world of Python, and inconsistencies in CloudFormation.
Enjoy!
Zen of Python
I have had Python in my tool belt of programming languages for over 20 years. Although it has seldom been the primary language I have worked with, it has been very useful and continues to be so.
Many years ago (1999), a guy named Tim Peters wrote Zen of Python, a set of guiding principles for writing software. They are not strictly tied to the Python language, but were written in that context, and something that fits well with some thoughts and ideas behind the design of Python.
If you start a Python interpreter, you can get these guiding principles by executing import this:
❯ python3
Python 3.11.2 (main, Feb 16 2023, 03:07:35) [Clang 14.0.0 (clang-1400.0.29.202)] on darwin
Type “help”, “copyright”, “credits” or “license” for more information.
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren’t special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you’re Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it’s a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let’s do more of those!
>>>Data oriented programming
I recently read the book Data oriented programming (DOP) by Yehonathan Sharvit. It is a quite nice book which describes a way of working with software design that aims to reduce a lot of complexity. Some ideas come from functional programming, but are not tied to that paradigm. In fact, most of the code examples in the book uses Java and JavaScript, with occasional references to C#, Python, etc.
There are four principles to use, to build software according to DOP:
Separating code (behaviour) from data
Representing data with generic data structures
Treating data as immutable
Separating data schema from data representation
The first principles are quite opposite what is commonly used in many object-oriented designs, where code and data are mixed up with each other in classes. The relationships and dependencies get more complex and complicated mix code and data, and you get simpler and more flexible designs if you keep them separate.
The second principles are also opposite to some designs found in both some object-oriented programming languages, and some functional programming languages with elaborate class and type hierarchies. The idea here is also to get more flexibility and better be able to re-use patterns and logic than if you tie these into strict and very specific data structures. Thus, you only use generic data structures such as lists, vectors, maps/dictionaries - not elaborate class hierarchies.
The third principle with immutable data has become more popular over the years, and makes it easier to reason about, and maintain and test software, where mutation can be restricted to specific areas of the code base.
The fourth principle is a necessity to support working with the other principles, in particular principle #2. Key areas to apply this is at the edges of your software (inputs and outputs with the world outside), but also internally where it makes sense to improve developer productivity. The book uses JSON Schema as the primary example of a separate data schema.
The book itself is written as a story, mainly with two characters - Theo, which is a senior developer at the company Albatross. After running into issues with improving and changing a piece of software written for a client, Theo finds some help from Joe, a developer who transitioned from object-oriented programming to data-oriented programming a few years ago.
Joe becomes sort of mentor to Theo and helps him redesign the software for the client using DOP principles. The result is that the software is easier to maintain and change, as the client comes with requests for improvements and changes.
Most of the book text is talks between Theo and Joe, and with some pieces with Theo’s colleague Dave, who is a more junior developer.
The book primarily uses JavaScript and Java to illustrate using DOP, but also have references to libraries and packages that help with DOP for a multitude of languages.
The author is a Clojure developer, and DOP is much in line with how software development is done in Clojure. In the book, though, Clojure is mentioned maybe 2-3 times at most, and just in passing. Same as with the book Grokking Simplicity that I wrote about in Tidy Cloud AWS #42, the message is that these principles can be applied in many languages.
I really enjoyed reading the book and having these principles described clearly, which was an eye-opener to me that these can be applied in a broader context.
This does not mean that this would work for all software, but there are many use cases where DOP can be applied. I recommend reading this book!
Pain of inconsistent CloudFormation in AWS
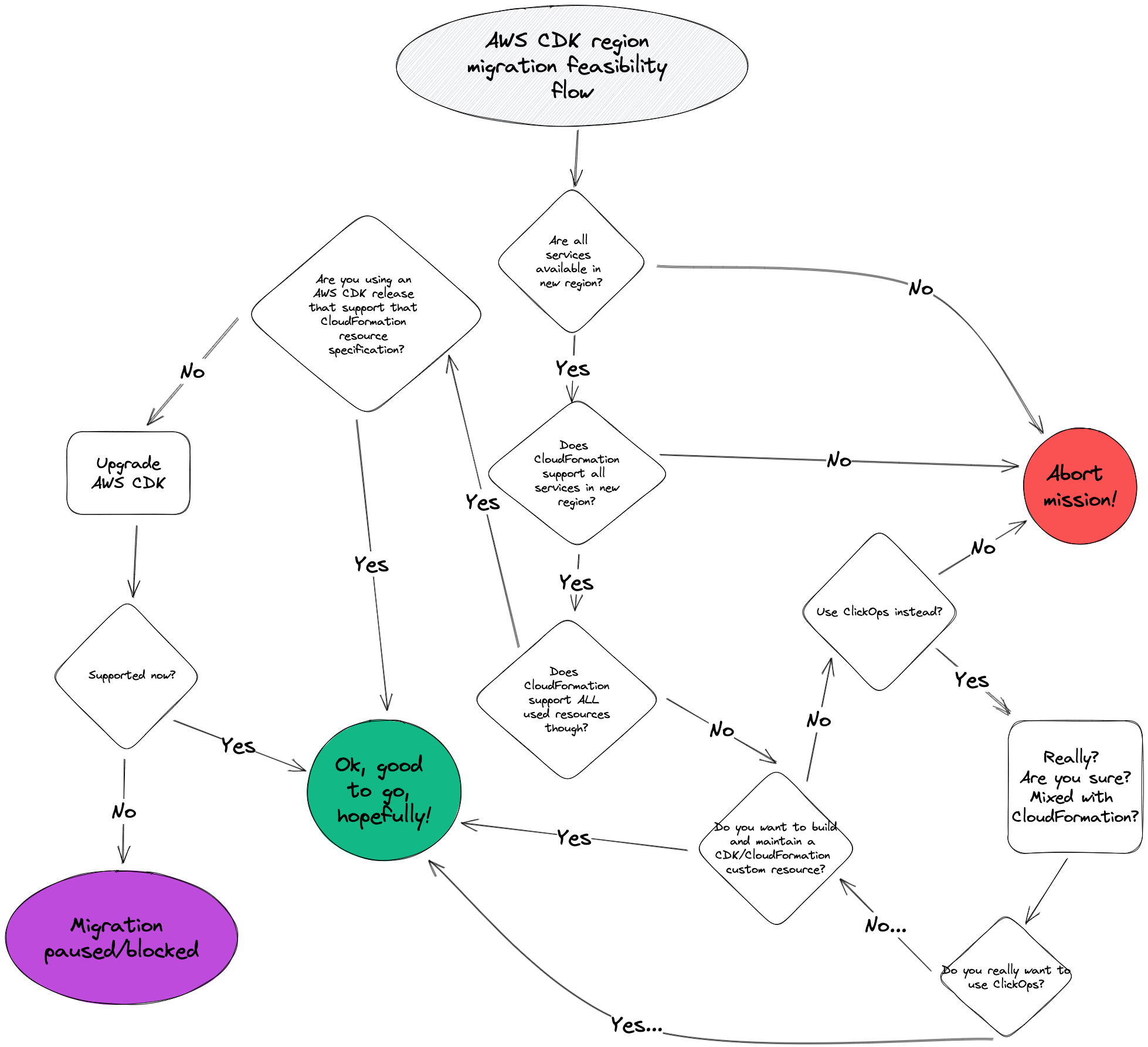
Recently, I have been involved in a task of moving a solution in AWS from one region to another, from Ireland to Stockholm in this case. The infrastructure for the solution is mainly defined with AWS Cloud Development Kit (AWS CDK). All needed services were supported in CloudFormation and thus by AWS CDK.
Having the solution defined as infrastructure-as-code, the transitions, in theory, are fairly smooth. This transition has been considered for a while, but not done because some services in use were only available in the Ireland region and not in Stockholm region.
Finally, though, all the needed services were available in Stockholm region, and it was deployed it there. One stack failed miserably with CloudFormation errors, though, about invalid resource types, for LakeFormation.
This was a case of inconsistent support for a service in CloudFormation. Even though a service is supported in a region, it does not mean that this service is supported by CloudFormation in that region, even if CloudFormation support exists in other regions.
Here, CloudFormation has LakeFormation support in Stockholm region, but not for all resources that are supported in Ireland…
This is actually not the first time I have run into this type of inconsistency (hello budgets and budget alerts), but it is frustrating when it happens. This incident inspired me to draw the flowchart below.
If you wants to check what CloudFormation supports in a particular region, check the CloudFormation resource specification.
Performance tradeoffs with AWS infrastructure as code
This blog post compares the time to set up some AWS cloud infrastructure using the service APIs directly, via Cloud Control APIs, via CloudFormation and via Service Catalog. It discusses some tradeoffs for the various use cases.
https://www.stedi.com/blog/relative-performance-tradeoffs-of-aws-native-provisioning-methods
I think this type of comparison is good, would also have been nice to include Pulumi and Terraform in a such a comparison.
Break-glass role
I saw a note about this repository from the Last week in AWS newsletter, where AWS has packaged an AWS CDK-based solution to deploy a break-glass role into your AWS set-up for emergency situations. Nice to see!
AWS DataOps Development Kit
AWS DDK is a framework built on top of AWS CDK, with a focus on building data pipelines. It includes several constructs to make this more convenient to build. It looks as if it is still in somewhat early stages. However, I like the idea of building toolkits/libraries/frameworks that target some specific use cases, but still allows to get into lower-level pieces if needed.
https://github.com/awslabs/aws-ddk
You can find older bulletins and more at Tidy Cloud AWS. You will also find other useful articles around AWS automation and infrastructure-as-software.
Until next time,
/Erik
You can find the contents of this bulletin and older ones, and more at Cloudgnosis.org. You will also find other useful articles around AWS automation and infrastructure-as-software.
Until next time,
/Erik