Have you struggled with increasing complexity of managing and maintaining software configuration? Some time ago, I saw a reference to what was called the Configuration Complexity Clock. It describes phases in how the complexity of software configuration grows. This name originally came from a blog post by Mike Hadlow in 2012.
This is something we should know and think about before we end up in a bad, unmaintainable place.
Mike Hadlow’s description resonated with me, and I have seen this pattern multiple times.
I work a with infrastructure-as-code, so I will mention some of these tools. However, the considerations expressed with the configuration complexity clock apply to any software, really.
In the infrastructure-as-code space, there are several tools available, for example
- AWS CloudFormation
- Terraform/OpenTofu
- Azure Resource manager
- Bicep
- AWS Cloud Development Kit
- Terraform Cloud Development Kit
- Pulumi
The latter three all use regular programming languages to describe cloud infrastructure.
They can be great for building abstractions to more maintainable infrastructure components. However, they also add complexity to the picture, because you get the full freedom of a regular programming language. Instead of hammer you get a nail gun - you can work some much quicker, but you can also hurt yourself more, if you are not careful.
So what is this idea of the configuration complexity clock?
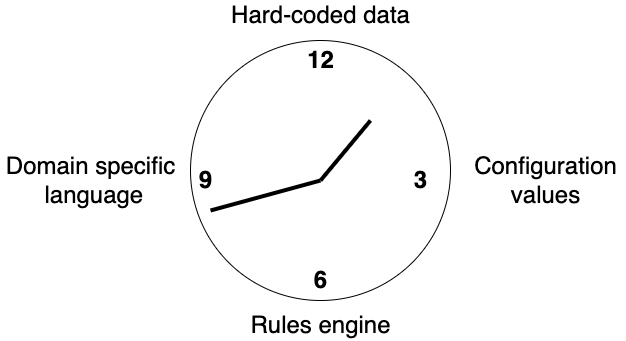
The simple starting point is at 12 o’clock, with a simple software-based solution where everything is hard-coded. Usually though in the design and work before it gets production ready, the need to make it configurable with come into play. This may be simple configuration values in a file, environment variables or command-line options. You just provide a value for a setting, and that is it. This may be at a time of deployment, or start time.
As the software develops, there may be a need to have some configuration shared between different components, and some may need to be updated in run-time instead. Configuration values may be stored in various types of shared data stores or databases. We are at 3 o’clock and go beyond that.
Eventually, providing different values may not be good enough. The business needs cannot be provided by just simple values, be it at deploy-time or run-time. It takes too long to let developers code the more complex business logic into software solution, so we may look at using rules engine to allow these things to be managed by people not deep into the software solution itself. So we establish rules engine, initially with some simple rule logic (e.g. if-then-else statements). We are at 6 o’clock.
The requirements get perhaps even more complex, and the rules engine is no longer enough. We need the power of an actual programming language! Here, it could end up into building a full-fledged domain-specific language (DSL). There is tremendous flexibility here, you can do almost anything with it!
Over time, though, these solutions became harder to understand. In particular, if there is a proprietary DSL, it will be hard to have people skilled in using and maintaining this solution.
In the end, it becomes just as complex to maintain as if it was hard-coded directly, and we have come full circle.
Where do our infrastructure-as-code solutions fit into this?
I would put solutions such as AWS CloudFormation, OpenTofu, Terraform, somewhere around 5 o’clock to 7 o’clock perhaps. They are a mix of configuration values and rules engine.
AWS CDK, Terraform CDK and Pulumi, I think they are in the 9o’clock to 12o’clock are in terms of expressiveness and potential complexity, but without some disadvantages that a custom DSL would bring.
In my experience, I have spent a fair amount of time building abstractions with tools like AWS CDK, to expose infrastructure at 3 o’clock complexity roughly to others. That can work great for those that use these abstractions, but it also means that I may become a bottleneck myself, if there are not enough people to build and maintain those abstractions. And these abstractions are often custom abstractions. Sometimes, it works out great, but in other cases, not as much.
AWS CDK is a very nice tool, but it does not provide alternate or simpler ways to express any abstractions you build. You still have to work with the programming language code, or build other interfaces on top of it.
It depends on your organisation whether that is a good fit for you. I see a lot of productivity gains with adopting something like AWS CDK, but also that too much of it may end up hurting productivity as well.
I wish I would have some solid advice here on what to use when, but I am looking for more options myself to consider. I think that configuration languages like CUE and Pkl are interesting to explore further and see how that fits, or tools like Crossplane which has some interesting ideas as well.
What do you think? What is your approach to managing configuration complexity?